Reliability and resiliency is a key, if not the most important piece, to the Nutanix Distributed File System (NDFS). Being a distributed system NDFS is built to handle component, service and controller (CVM) failures.
“Reliability is the probability of an item operating for a certain amount of time without failure. As such, the reliability function is a function of time, in that every reliability value has an associated time value.” – Reliability Hotwire
“Resiliency is the ability to provide and maintain an acceptable level of service in the face of faults and challenges to normal operation.” – wikipedia.com
The Nutanix cluster automatically selects the optimal path between a hypervizor host and a guest VM data. This is known as automatic path direction, or Autopath.
When local data is available, the optimal path is always through the local CVM to local storage devices. However, in some situations, the VM data is not available on local storage, such as when a VM was recently migrated to another host. In those cases, the CVM re-directs read request across the network to storage on another host.
Nutanix Autopath also constantly monitors the status of CVMs in the cluster. If any process fails to respond two or more times in a 30-second period, another CVM will redirect the storage path on the related host to another CVM. To prevent constant switching between CVM, the data path will not be restored until the original CVM has been stable for at least 30 seconds.
A CVM “failure” could include a user powering down the CVM, a CVM rolling upgrade, or any event, which might bring down the CVM. In any of these cases autopathing would kick-in traversing storage traffic transparently to be served by another CVM in the cluster.
The hypervisor and CVM communicate using a private network on a dedicated virtual switch. This means that all storage traffic happens via an internal IP addresses on the CVM. The external IP address of the CVM is used for remote replication and for CVM to CVM communication.
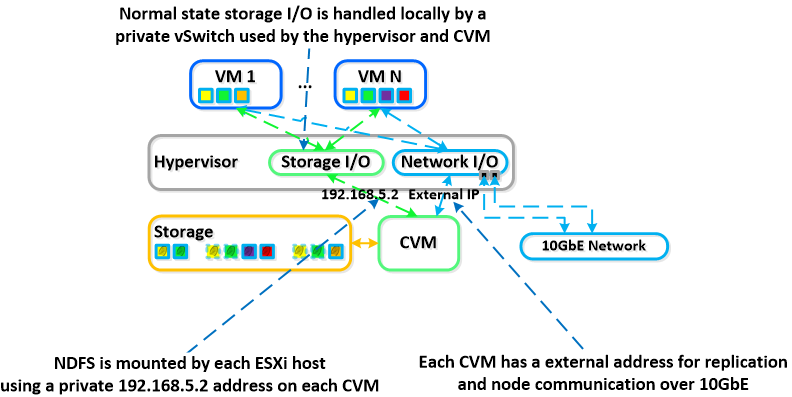
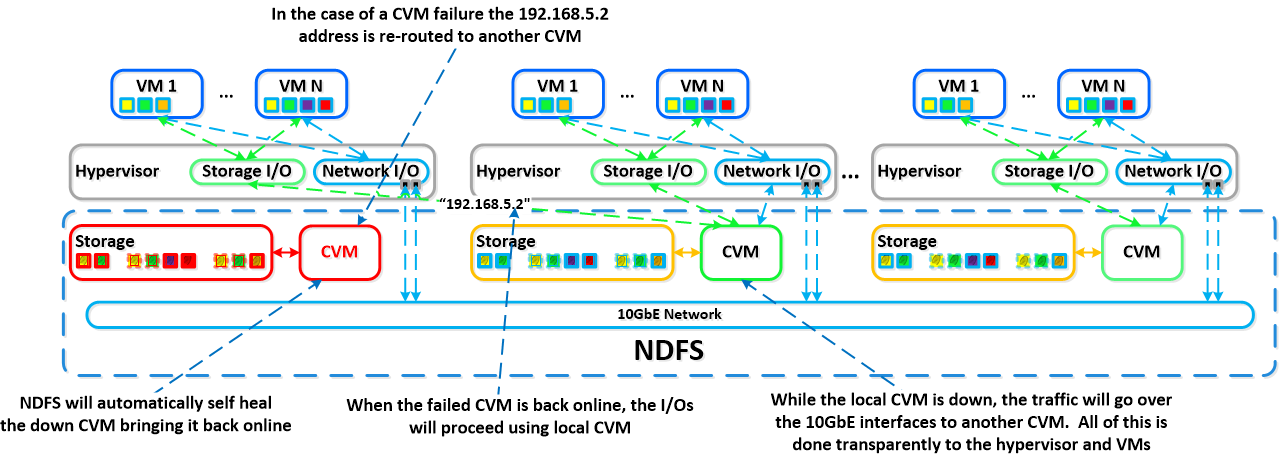
In the event of a local CVM failure the local addresses previously used by the local CVM becomes unavailable. In such case, NDFS automatically detects the outage and redirect storage traffic to another CVM in the cluster over the network. The re-routing is done transparently to the hypervisor and to the VMs running on the host.
This means that even if a CVM is powered down the VMs will still continue to be able to perform IO operations. NDFS is also self-healing meaning it will detect the CVM has been powered off and will automatically reboot or power-on the local CVM. Once the local CVM is back up and available, traffic will then seamlessly be transferred back and start to be served by the local CVM.
NDFS uses replication factor (RF) and checksum to ensure data redundancy and availability in the case of a node or disk failure or corruption. In the case of a node or disk failure the data is then re-replicated among all nodes in the cluster to maintain the RF; this is called re-protection. Re-protection might happen after a CVM is down.
Below we show a graphical representation of how this looks for a failed CVM:
What Will Users Notice?
During the switching process, the host with a failed CVM may report that the datastore is unavailable. Guest VMs on this host may appear to “hang” until the storage path is restored. This pause could be as little as 15 seconds and only be noticed as a surge spike in latency. Although the primary copy of the guest VM data will be unavailable because it is stored on disks mapped to the failed CVM, the replicas of that data are still accessible. As soon as the redirection takes place, VMs can resume reads and writes.
The performance may decrease slightly, because the IO is now traveling across the network, rather than across the internal virtual switch. However, because all traffic goes across the 10GbE network, most workloads will not diminish in a way that is perceivable to users.
This behavior is very important as it defines Nutanix architecture resiliency, allowing Guest VMs to keep running even when there is a storage outage. In other solutions, where the storage stack is not independent, a failure or a kernel panic could potentially force Guest VMs and applications to have to be restarted in a different host, causing serious application outages.
[Important Update] As of NOS 3.5.3.1 the VM pause is nearly imperceptible to Guest VMs and applications.
What happens if another CVM fails?
A second CVM failure will have the same impact on VMs on the other host, which means there will be two hosts sending IO requests across the network. More importantly, however, is the additional risk to guest VM data. With two CVMs unavailable, there are now two sets of physical disks that are inaccessible. In a cluster with a replication factor of two, there is now a chance that some VM data extents have become unavailable, at least until one of the CVMs resumes operation.
However if the subsequent failure occurs after the data from the first node has been re-protected there will be the same impact as if one host had failed. You can continue to lose nodes in a Nutanix cluster provided the failures happen after the short re-protection time, and until you run out of physical space to re-protect the VM’s.
Boot Drive Failure
Each CVM boots from a SATA-SSD. During cluster operation, this drive also holds component logs and related files. A boot drive failure will eventually cause the CVM to fail. The host does not access the boot drive directly, so other guest VMs can continue to run. In this case NDFS Autopath will also redirect the storage path to another CVM. In parallel, NDFS is constantly monitoring the SSDs to predict failures (I’ll write more about it in the future).
Thanks to Steven Poitras for allowing me to use content from The Nutanix Bible.
Thanks to Michael Webster, Josh Odgers and Prasad Athawale for contributing and revising this article.
This article was first published by Andre Leibovici (@andreleibovici) at myvirtualcloud.net.