Nutanix introduced the first Hyperconverged platform to the market in 2011. While other Hyperconverged solutions have since come out, what differentiates Nutanix from the other solutions is the focus on implementing a highly scalable, reliable and performant distributed systems architecture. As the first engineer at Nutanix, I was involved in developing one of the core pieces of this distributed system – the distributed metadata subsystem and I wanted to talk about some of the salient features of the Nutanix metadata store. In case you were wondering what is metadata, it describes where and how data is stored in a file system, letting the system know on which node, disk, and in what form the data resides. Metadata store is where all this metadata gets stored.
Nutanix Hyperconverged platform is powered by the Acropolis Distributed Storage Fabric or ADSF (Previously known as Nutanix Distributed File System or NDFS). ADSF is a scalable distributed storage system which exposes NFS/SMB file storage as well as iSCSI block storage API with no single point of failure. The ADSF distributed storage fabric stores user data (VM disk/files) across different storage tiers (SSDs, Hard Disks, Cloud) on different nodes. ADSF also supports instant snapshots, clones of VM disks and other advanced features such as deduplication, compression and erasure coding. You can learn more about the product and its capabilities here.
ADSF logically divides user VM data into extents which are typically 1MB in size. These data extents may be compressed, erasure coded, deduplicated, snapshotted or untransformed vanilla user data bits! The granularity of deduplicated and snapshotted extents may get reduced from 1MB to be as small as few KBs. The data extents can also move around; hot extents stay on faster storage (SSD) while colder extents move to HDD. Furthermore the extents get stored closer to the node running the user VM providing data locality and may move once the VM moves to another node. To support all the above functionality and features, the ADSF metadata is very granular and can be fairly complex and large in size. The size and performance requirements for the metadata store along with distributed systems architecture of ADSF necessitated that the ADSF metadata store implementation be a shared nothing fully distributed system in itself. The ADSF metadata store, internally called Medusa Store, is a NoSQL key-value store built on top of heavily modified Apache Cassandra.
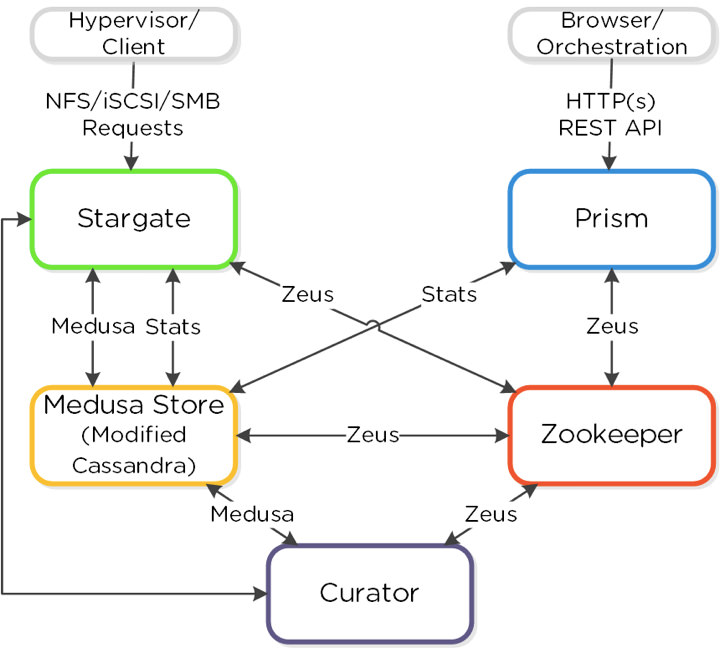
Medusa Store, like other competent distributed key-value stores out there, has no single point of failure, with every node having symmetric capabilities. The shared nothing architecture of Medusa Store allows it to scale its performance and storage footprint linearly with the number of nodes. Unlike other open sourced key-value stores in market, Medusa Store really shines through when it comes to providing strong consistency guarantees along with unmatched performance (more on this below). Unlike traditional distributed storage systems, ADSF doesn’t use a Distributed Lock Manager for synchronizing data and metadata access. Fine-grained control of data and metadata through Distributed Lock Managers is notoriously hard to get right. Instead ADSF protects the VM disk (a.k.a vdisk) data by a coarse vdisk lock. Any access that logically modifies vdisk data will be done by the node that holds this lock – the owner for the vdisk. This is usually the node on which the VM is running. However this coarse level vdisk lock doesn’t protect VM metadata which is more fine grained and can be shared across vdisks. Most of the time the metadata is not shared between vdisks and the top level vdisk lock ensures that vdisk metadata gets accessed from a single node. But then there are cases where metadata is shared across vdisks such as with snapshots, deduplication and/or erasure coding. Also there may be races in accessing metadata when ownership of vdisk moves between nodes. In these cases the same metadata may be accessed (read/written) concurrently from different nodes. Now, you may wonder what happens if two nodes try to mutate the same metadata concurrently and what happens if failures occur while ADSF was in the process of making these changes. In that case it’s necessary to have a fail-safe – a way to synchronize concurrent access of metadata from multiple nodes and a way to rollback (or roll forward) changes that were in flight when a failure occurs. Medusa Store comes to the rescue in both cases. Below, I describe the most important features of Medusa Store and how they help solve the problems I describe above –
- Atomic Compare and Swap – ADSF assumes that any modification to user data has to finally update metadata for the write to be successful and be visible to the user VM. Concurrent operations trying to change the same data will have to update the same metadata key(s). Medusa Store provides Atomic Compare and Swap (CAS) API for synchronizing writes for these metadata key(s). Atomic CAS avoids (and allows ADSF to detect) the case when components try to step on each others feet trying to change the same data. Atomic CAS ensures that when two competing writes try to change the same metadata key, only one of them succeeds while the other fails. Now one may ask about how does one provide Atomic CAS on a distributed key-value store? At the heart of Medusa Store is an efficient implementation of Paxos distributed consensus protocol. Paxos algorithm ensures that if and when multiple values are proposed for a key only one value succeeds (chosen). Concurrent writes to the same metadata key will run Paxos protocol with only one write succeeding, logically providing CAS functionality! ADSF employs Atomic CAS to implement transactions when performing writes which maintains consistency in face of failures. The order of the metadata changes by ADSF is such that any failures midway during a write will not leave data inconsistent. The changes that were mid-way when failure occurred may be rolled back or rolled forward depending on the state of the metadata and data the next time the data is read/written.
- Performance – Implementing Paxos protocol can be tricky and it’s common practice to compromise on performance for ease of implementation. We didn’t take any shortcuts when we implemented the Medusa Store. Our Paxos implementation is optimal – minimum number and size of messages possible get exchanged between replica nodes when doing Paxos reads/writes. The standard Nutanix NX 3060 cluster can do tens of thousands of Paxos metadata reads/writes per second per node.
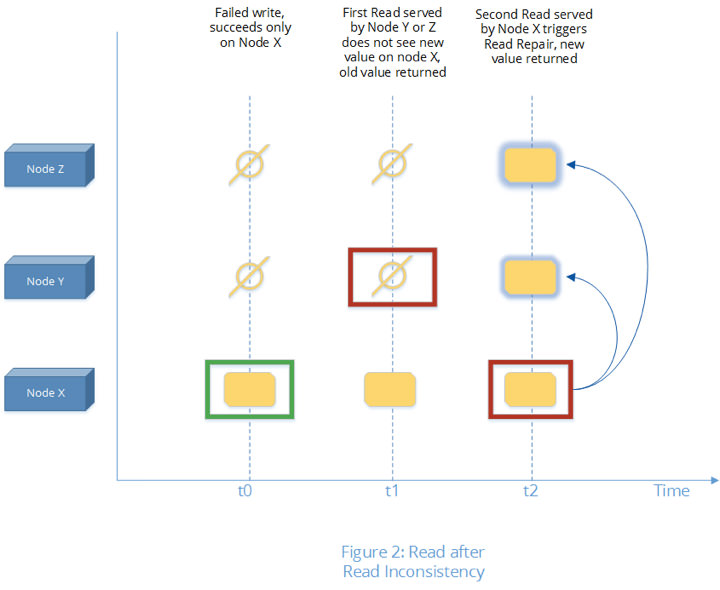
- Consistency – Medusa Store provides several strong consistency guarantees such as Write-after-Write, Read-after-Write, and its more trickier counterpart Read-after-Read consistency. While atomic CAS and Read-after-Write consistency are fairly well known, Read-after-Read consistency guarantee is a bit more tricky for distributed storage systems. In its essence it requires that a client doing a read at time t1 and repeating the read at time t2 without a write in between t1 and t2 must see the same result. For distributed systems, Read-after-Read consistency gets tricky as the following example illustrates.
- Let’s assume client attempted a write at time t0, which, although failed in its entirety, succeeded on one of the three replica nodes, node X.
- Subsequent reads at time t1 (t1 > t0) consult the other two replica nodes Y and Zthat haven’t received the write and hence see old data.
- It’s possible that the next read at time t2 (t2 > t1) consults replica X which reports the newer value. This new value can also get transferred to the other two replicas Y and Z in the background, succeeding a write that failed earlier (this is termed as ‘read-repair’). In such a case the client will suddenly see a flip in the value for the key without a write in between. Such a behavior, although considered valid in the eventually consistent key-value stores, will not work for ADSF metadata store. ADSF implements file system (NFS, SMB) and block storage (iscsi) and its metadata can’t flip flop, or else it will cause the VM disks to see corruption.The Medusa Store ensures Read-after-Read consistency guarantee is always maintained.
On a read, either the Medusa Store ensures that all replicas are in sync and the read can be safely completed, or if a discrepancy between replica nodes is detected, the read fixes the discrepancy before completing the read. This is ensured even if the replica that has the latest data from an incomplete write, node X in the example above, is down. Medusa store, building on top of the key’s internal Paxos state can determine if the node that is down can possibly have an incomplete write. If such a case is determined to be possible, the Medusa Store runs a new Paxos write to bump the version of the current value which negates the incomplete write at the replica that is down.
- Reliability and Availability – Medusa Store with Replication Factor (RF) of 3 can take one node failure and with RF 5 Medusa store can take two node failures while still maintaining the hard consistency and performance characteristics mentioned above. When performing a Paxos write, for efficiency, we do not wait for all replicas to complete their write but only for the quorum number of replicas to finish. The nodes can go up and down in any sequence but until quorum number of replicas are available (only one node is down or two nodes for RF 5), the Medusa store keeps on working without availability or performance issues. This allows ADSF to support features such as one click rolling upgrades, High Availability etc. Needless to say that the consistency guarantees mentioned above continue to hold when nodes go down, come back up or when new nodes are added to the cluster and they add themselves to be part of the Medusa Store. All in all this ensures that Nutanix delivers truly invisible infrastructure. Our customers get a seamless experience managing their Nutanix clusters and don’t worry about failures causing storage issues.
Medusa Store, although initially designed to store ADSF metadata, is generic enough to be the backing store for several other ADSF services. Our internal distributed Write Ahead Log (WAL) implementation and Entity DB storing configuration for all VMs, internal objects and stats reside on top of Medusa store as well.
To summarize, for an enterprise storage system like ADSF, consistency and correctness is everything. This needs to pervade all of ADSF internal subsystems including its metadata subsystem. ADSF metadata store is a NoSQL distributed key-value store which has an optimal implementation of the Paxos consensus protocol. ADSF metadata store really pulls ahead from Apache Cassandra and other distributed key-value stores where consistency can sometimes be an afterthought and ‘eventual consistency’ is considered good enough in the name of simplicity and performance.