Replication is a fundamental component of any enterprise disaster recovery (DR) solution, ensuring that critical data and applications can be reliably and efficiently replicated to a different site or a separate infrastructure. While enterprise IT architects have many technology options, there are two replication capabilities that are requisite for any successful enterprise DR initiative.
- Per-VM backup – The ability to designate certain VMs for backup to a different site is particularly useful in branch office environments. Typically, only a subset of VMs running in a branch location require regular back up to a central site. Such per-VM level of granularity, however, is not possible when replication is built on traditional storage arrays. In these legacy environments replication is performed at a coarse grain level, entire LUNs or volumes – making it difficult to manage replication across multiple sites.
- Selective bi-directional replication – In addition to replicating selected VMs, a flexible replication solution must also accommodate a variety of enterprise topologies. It is no longer sufficient to simply replicate VMs from one active site to a designated passive site, which can be ‘lit up’ in event of a disaster. Supporting different topologies demands that data and VMs can be replicated bi-directionally.
Nutanix’s native replication infrastructure and management supports a wide variety of enterprise topologies to meet real-world requirements, including:
1. Two-way mirroring – The ability to mirror VM replication between multiple sites is necessary in environments where all sites must support active traffic. Consider a two-site example. Site 2 is used as the target for selected workloads running on Site 1. At the same time, Site 1 serves as the DR target for designated workloads running at Site 2.
In this scenario there are active workloads running on both sites simultaneously, such that there are no idle resources in either location. Utilizing storage, compute and networking resources at both locations has a significant advantage over traditional DR strategies where servers sit idle in anticipation of a future DR event.

2. One-to-Many – In a different scenario, there may be one central site with multiple remote locations. Consider an example where tier-one workloads run at site 1, and sites 2 and 3 serve as remote back-up locations. Site 1 workloads can then be replicated to both 2 and 3 locations. In the event of a DR event, the protected workloads can be started on either the desired replication sites for greater overall VM availability.
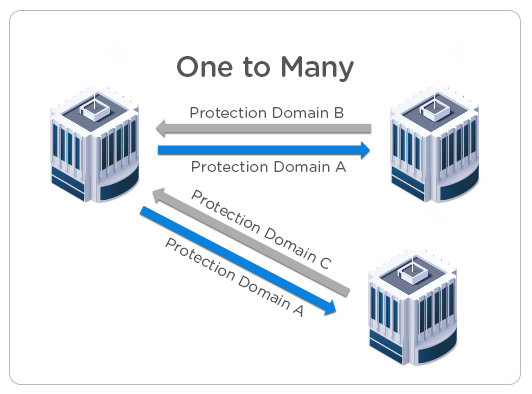
Further, a one-to-many topology can also be designed to optimize bandwidth between sites. For example, assume the available wide area network (WAN) bandwidth between sites 1 and 3 is greater than that between sites 1 and 2. (1 and 2 sites could be in the same city, whereas site 3 may be across the country).
In this case, the replication schedule can be set such that larger size VMs running at site 1 are replicated to site 2 in order to conserve bandwidth and improve performance. Similarly, smaller VMs will be backed up to site 3, to make better use of lower bandwidth resources.
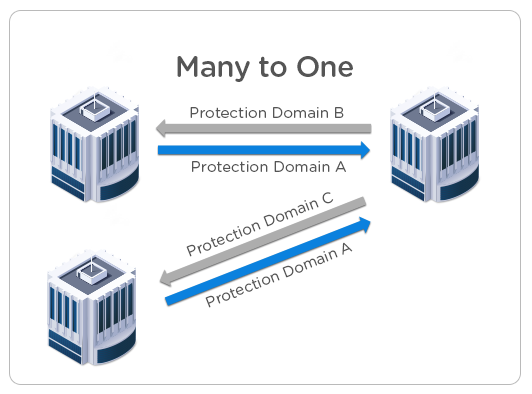
3. Many-to-One – In a hub and spoke architecture workloads running on site 1 and 2, for example, can be replicated to a central site 3. Centralizing replication to a single site may improve operational efficiency for geographically disperse environments. Remote and branch offices (ROBO) are a classical use case of a many-to-one topology. For example, an NX-1000 in a remote office can replicate to an NX-3000 or NX-6000 series in the data center.
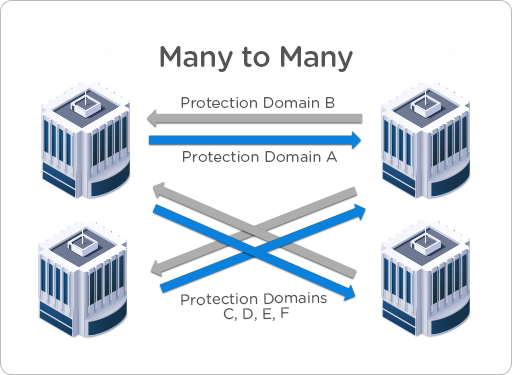
4. Many-to-Many – This final topology allows for the most flexible setup. Here, IT departments have a maximum amount of control and flexibility to ensure application and service level continuity.
Nutanix’s native per-VM replication provides support for flexible disaster recovery (DR) topologies and strategies. This empowers virtualization administrators to set replication policies that meet application-specific requirements, satisfy custom RPO and RTO needs and intelligently conserve bandwidth between geographically distributed sites.