When we introduced Nutanix Objects in the market, our commitment was (and still remains) to build a SIMPLE, SECURE and SCALE-OUT stack. As customers have adopted, they have been (pleasantly) surprised by how simple it is to spin up the Nutanix Objects service. In three simple steps (give it a name, choose cluster size and provide networking info), you can spin up an object service in approximately 45 mins that can start super-small (1TiB small) and scale to multiples of PBs. Coming from spending and planning days, and struggling with CLI/scripts etc in getting a legacy object store running, Nutanix Objects deployment looks like a child’s play. As if to prove that point, one of our SAs got a non-technical person to deploy Objects during a live demo in front of a room full of IT experts :-)
1-CLICK SCALE-OUT TO MULTI-CLUSTER GLOBAL NAMESPACE
Object stores, by the nature of the workloads they serve, can get very, very large over a period of time. I am talking about tens of PBs. At some point in time, the cluster you started your object store on is bound to run out of storage capacity. Or, you might feel reluctant just blindly adding more & more nodes to a cluster for failure domain reasons. Then what? Traditionally, people have considered either migrating a few workloads from that cluster to another, or migrating (moving off) data from that cluster to another. Both of these are painful, to say the least, involving weeks and months of project planning.
I have talked about entropy in a previous blog – left of their own accord, things tend to get complex. Keeping things simple takes an enormous amount of energy. While working on Objects 2.0, we kept asking ourselves how can we address the ever increasing need for storage without disrupting applications, or forcing admins to do data migration. Instead of designing the next generation “storage vmotion”, can we make “storage vmotion” unnecessary?
With Objects 2.0, you can now tame the rapidly growing unstructured data sets in your environments without resigning to a fate of daily/weekly capacity planning meetings, or being forced to do data migration, all with 1-click. How, you ask – by extending an existing Nutanix Objects running on a cluster to consume capacity from other Nutanix clusters within a data center.
Illustration:
- Say, you have deployed a 4-N Objects cluster (cluster A). As capacity gets consumed, you might feel the need to expand that cluster by adding more nodes.
- However, if you have another Nutanix AOS cluster (cluster B) somewhere that might have some free storage capacity available, you can simply add that cluster B to the Objects cluster A. The “add” is a virtual add – all you are doing is letting Objects consume capacity from cluster B, just as it is consuming capacity from cluster A. Neat, huh.
- But what about Objects consuming more capacity from cluster B than I wanted it to consume – well, that’s why we have guardrails. You can define the extent to which Objects can consume capacity from all “secondary” clusters. E.g. you can specify that Objects consume no more than 20% of cluster B capacity. And so on.
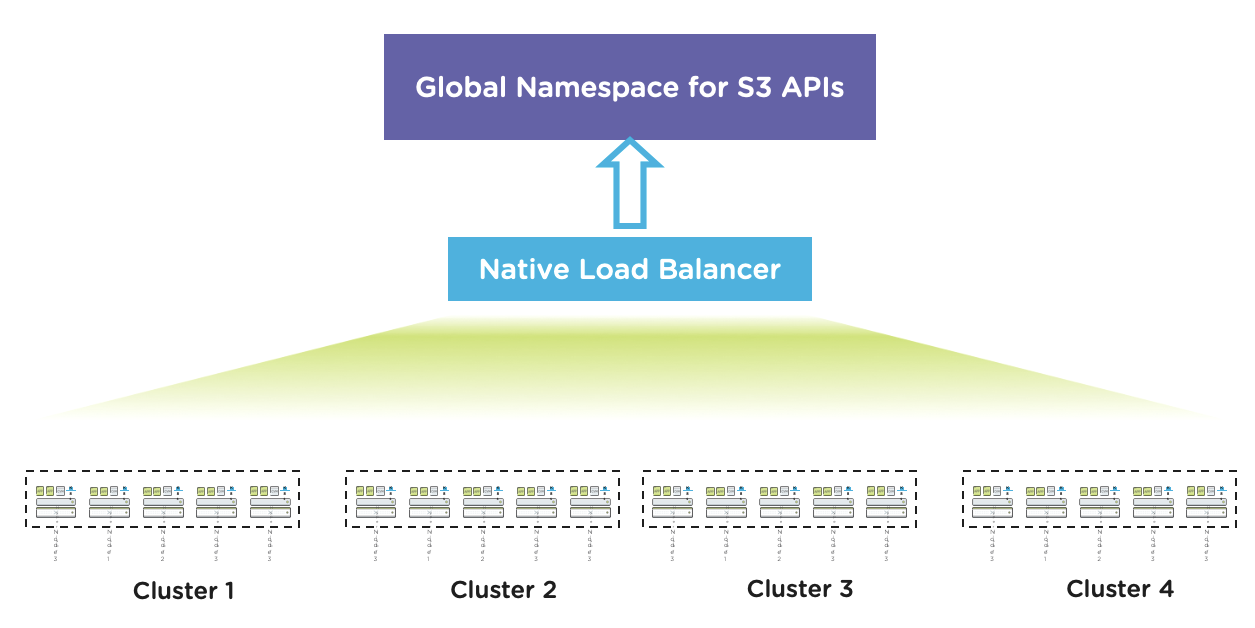
Where this is useful:
- This gives a new meaning to scale out and capacity planning. You can choose denser nodes to build your Objects cluster (more on that later in the blog) , add nodes, add new/existing clusters to provide more capacity to Objects.
If you are like any large enterprise customer we have, you might have multiple Nutanix clusters already in your data center, some of which might not be fully utilized in terms of storage just yet. Well, now you can pool all that disparate capacity, and use that for Objects. Think about getting your developers an S3-compatible endpoint, without spending a penny on hardware, racking/stacking/cooling etc.
INTRODUCING 240TB NODES FOR NUTANIX OBJECTS
As we have noted before, Nutanix Objects is designed for performance. Designing a software stack for performance ensures that bottlenecks shift to hardware. This enables us to size to varying customer requirements using the same software, but by choosing the correct node types, all the way from NVMe/All Flash nodes (high performant) to hybrid nodes with just a sliver of SSDs (cost effective). But what do you do when you need good performance at a super low price?
Introducing the 240TB nodes – with 20 HDDs and 4 SSDs. In a hybrid node, performance is often dictated by the no. of HDD spindles. We zeroed in on the 24 drive in 2U form factor for two reasons:
- Performance: A clever use of the SSD tier with 20 HDDs per node ensures great performance.
- Cost Effectiveness: Given the drives are 12TB LFF HDDs, it enables our customers to pack a lot of data in a cost and density effective manner.
Rebuild time is an important consideration when productizing large capacity nodes. This is where our focus on improving rebuild speeds over the past few releases (we have essentially more than doubled it) helps.
WELCOME, SPLUNK SMARTSTORE!
So far, we have talked about the SIMPLE and SCALE-OUT aspects of Objects. Let’s focus on SECURE now. More and more IT organizations are having to store an enormous amount of logs for years to ensure compliance. More often than not, Splunk is the tool of choice for them. The challenge the ever growing log-storage requirement poses is where to store the growing data set (so scale is important) and how to store it in a cost effective manner (price).
To address these challenges, Splunk has introduced the Splunk SmartStore architecture. SmartStore enables Splunk customers to use object storage for their data retention requirements. Splunk can talk to an S3-compatible object store natively. This is where Nutanix Objects fits in as Objects is ready to run Splunk SmartStore. Nutanix Objects provides a massively scalable, easy to use, cloud-integrated and secure object store solution at an object store price point.
As a customer if you have Splunk running in your environment, please reach out to us on how we can help you transition to SmartStore.
WORM WITH NON-VERSIONED BUCKETS
There is more on security. Nutanix Objects already supports an AWS S3 compliant WORM (Write Once Read Many) implementation. Once a bucket is declared WORM, for that time period, data is locked – it cannot be deleted or modified. It is a strict “compliance WORM” implementation – meaning no one, not even super admins or Nutanix engineers can disable that WORM policy, or reduce the time period (duration can be extended though).
One of the aspects of being S3 compliant is that versioning on such buckets need to be enabled always. Based on customer feedback, we realized that some applications do not yet support versioning. They needed WORM on non-versioned buckets. So we have extended our WORM implementation to support it on non-versioned buckets now with Objects 2.0.
With Objects, our mission is to bring *simplicity* to unstructured data management, or as I call it - the amorphous blob. Only when we get a handle on this black box of amorphous blob can we start deriving meaningful action oriented information that can help drive your businesses. Looked at from that angle, storing the “blob” is just one piece of the puzzle. Performance (e.g. ability to run analytics on the blob natively), security-first approach, and doing all this in a scalable and operationally efficient manner is the journey from blob to information. That’s what we are committed to providing our customers.
TRY IT OUT!
If you're already a Nutanix customer, you can try Nutanix Objects in your own environment today with unused capacity you already have. Every AOS cluster is entitled to 2TiB of Objects license for free. What’s more - if you have multiple AOS clusters, say 5 of them, you can pool your Objects licenses and use up to 10TiB of Objects for free. Watch this 3-min video to see how easy it is to try this simple, scalable, and secure solution for your object storage needs.
Priyadarshi Prasad
Sr. Director, PM
© 2020 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site. Certain information contained in this post may relate to or be based on studies, publications, surveys and other data obtained from third-party sources and our own internal estimates and research. While we believe these third-party studies, publications, surveys and other data are reliable as of the date of this post, they have not independently verified, and we make no representation as to the adequacy, fairness, accuracy, or completeness of any information obtained from third-party sources.