Ensuring Resilient Mission-Critical Applications
By Sujaikumar Jayarao, Director PM DR
Introduction
Reliance on mission-critical applications has never been greater than now. From financial transactions to healthcare records management, emergency services, stock exchange trading, and many more, these applications serve as the lifeblood of enterprise operations. Their continuous availability is paramount for maintaining business continuity, safeguarding financial stability and upholding public safety.
However, the challenge intensifies when businesses must consider the potential failure of two fault domains simultaneously. This scenario underscores the critical need for a third fault domain to enhance redundancy and resilience in the face of unforeseen disruptions.
Considering these critical factors, the Nutanix Cloud Platform (NCP)™ designed solution is meticulously engineered with built-in rack-level and node-level high-availability features, including fault management for disks, network cards and power supplies.
Furthermore, seamless integration of data protection capabilities optimizes the resilience of mission-critical applications. Leveraging the Nutanix Disaster Recovery (DR) solution, we extend continuous availability to multiple clusters through comprehensive recovery plans and meticulous runbook planning.
Nutanix Disaster Recovery
In the Nutanix DR journey, we've developed robust replication solutions that are tailored to various Recovery Point Objectives (RPOs) and Recovery Time Objectives (RTOs).
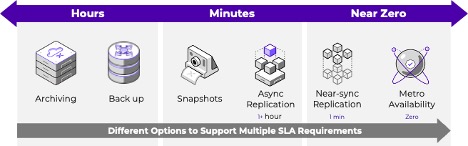
At the core of our operations are snapshots, which serve as point-in-time copies of application data. Immutable and secure, these snapshots can be captured at various intervals and tailored to the unique needs of businesses, locally and remotely. They are retained for different durations to ensure data integrity and flexibility in data management strategies.
Asynchronous replication, with intervals of 1 hour and above, offers a balance between data protection and performance, allowing organizations to recover data from a recent point in time.
Nearsync replication, with intervals ranging from 1 to 15 minutes, provides enhanced data protection by reducing potential data loss. It uses Lightweight Snapshots (LWS), which are OpLog-based markers, running on solid-state drives (SSDs). Since the time taken by LWS is a constant O(1) (constant time taken no matter the data size), there is minimal impact on the user IO. This architecture makes LWS highly scalable and distributed. LWS is replicated continuously to the remote site.
Synchronous replication offers real-time data replication with zero data loss. It is designed to operate between sites with latency under 5 ms. By maintaining a secondary copy of all data – including VM data, VM metadata and protection policies across two clusters – continuous application availability and zero data loss are ensured in the event of a site failure. This architecture also enables seamless VM live migration between sites to further enhance resilience and flexibility in managing workloads.
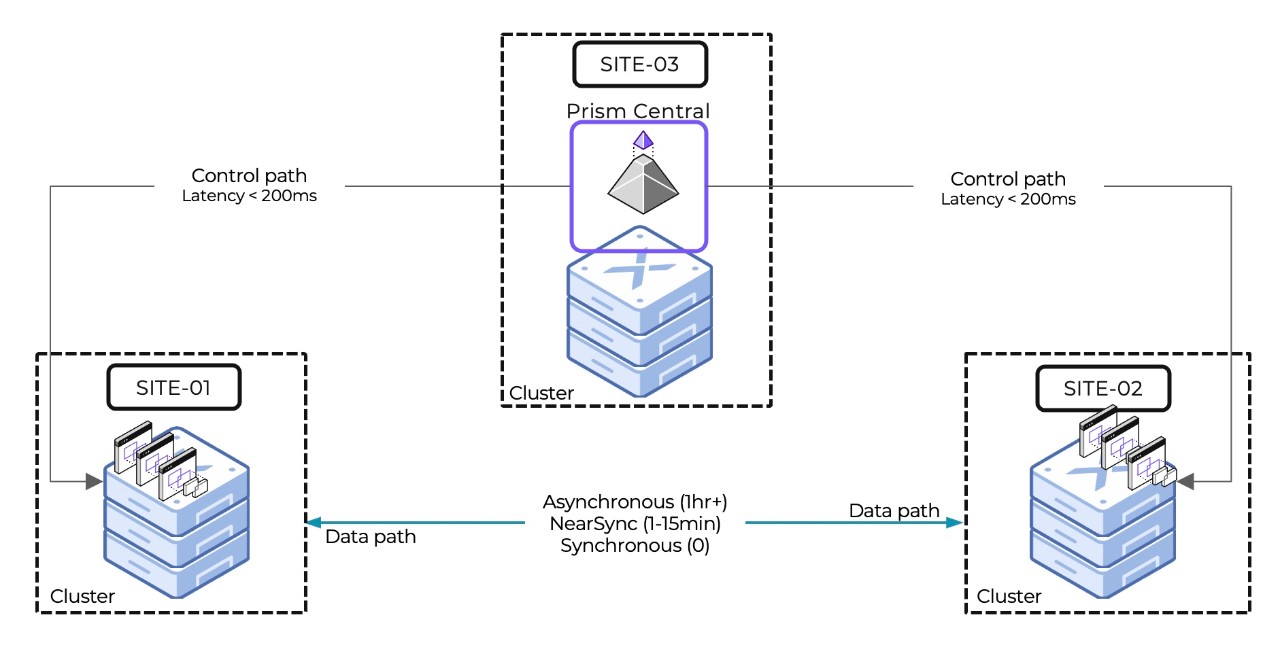
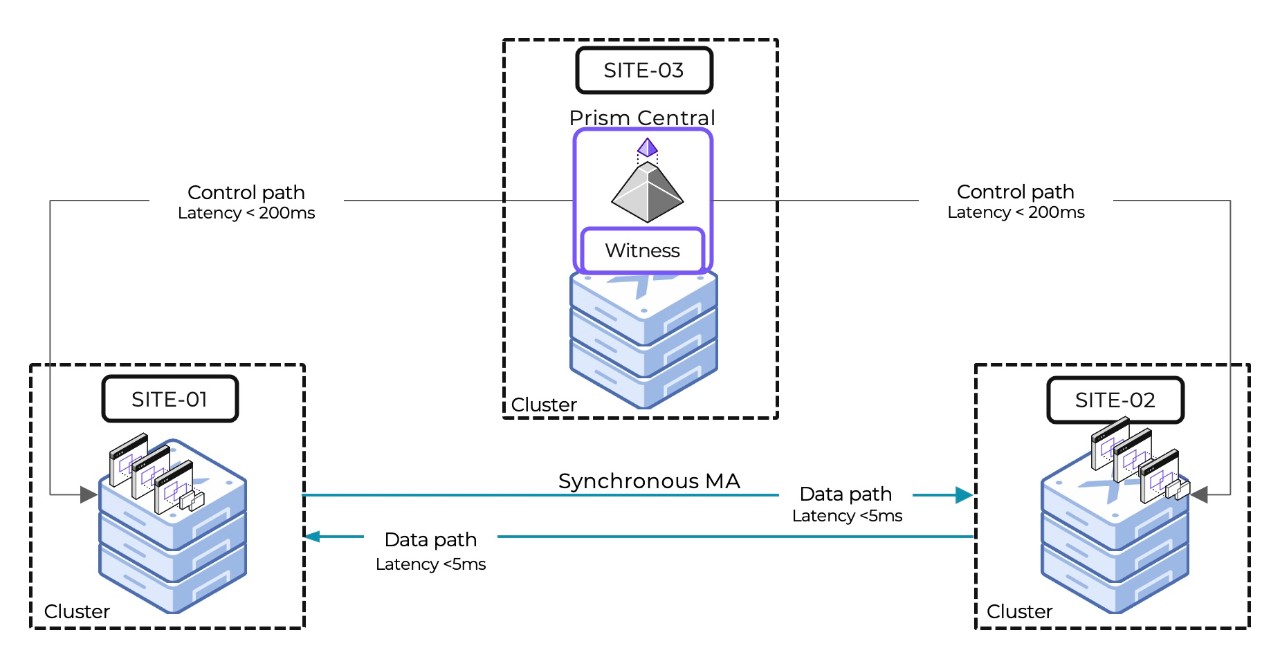
Metro Availability (MA), serves as a powerful solution that addresses the dual needs of availability and compliance requirements. Implementing Metro Availability across two sites enhances the Synchronous replication by automating failover capabilities.
Metro Availability creates a zero-touch disaster recovery solution, ensuring continuous operation in the face of site failures. The automatic failover is facilitated by the Witness Service hosted in a separate fault domain, which further enhances system reliability and resiliency.
Orchestrating Recovery: The Crucial Elements of a Robust DR Solution
While establishing redundancy for workloads is feasible through methods like snapshots and replication, orchestrating the recovery process is an indispensable part of a resilient DR solution. What enhances its efficacy is the consolidation of replication and recovery workflows within one unified product offering.
Runbooks for recovery orchestration serve as a valuable complement to Nutanix replication options. They offer a range of functionalities such as defining the order of entity recovery, configuring complex network IP mapping and executing custom scripts.
In addition, built-in features like Planned Failover (PFO), Unplanned Failover (UPFO), and Test Failover (TFO) further enhance the solution’s robustness by providing comprehensive recovery orchestration capabilities.
PFO facilitates site maintenance, node upgrades, migrations, and other planned operational tasks. It allows administrators to orchestrate controlled failovers for routine maintenance activities for one or more applications or workloads.
On the other hand, UPFO is invaluable during unexpected site-level disasters or cluster-level failures. In such critical situations, the Metro Availability solution automatically triggers UPFO failover processes to ensure rapid recovery and minimal disruption to business operations.
TFO provides a crucial testing mechanism for validating failover configuration to an isolated environment before executing the failover process in production. By simulating failover scenarios in a controlled environment, TFO allows organizations to verify the preparedness and effectiveness of their DR plans and proactively identify potential issues or gaps.
Together, these features offer comprehensive capabilities for orchestrating failover processes tailored to different scenarios, while ensuring resilience and continuity of operations in the face of planned and unplanned events.
Importance of Network Security and Overlay Networks
Protecting critical applications from malicious actors is a top priority for organizations. Nutanix recognizes this need and provides robust, integrated network tools in all Nutanix DR solutions.
The Nutanix Flow Virtual Networking (FVN)™ solution is a software-defined networking offering that ensures multi-tenant isolation, self-service provisioning and IP address preservation.
Additionally, Nutanix Flow Network Security (FNS) provides a software-based firewall per node, enhancing security without adding management overhead. These features collectively bolster the resilience of critical business applications – a particularly significant feature in the context of Metro Availability – where human touchpoints are minimal.
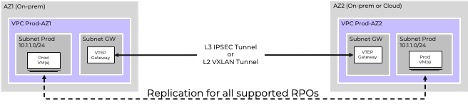
Extending Resilience with Three-Site Redundancy
Organizations can strengthen their resilience by extending Metro Availability to include a third site. In scenarios where two sites experience failures simultaneously, the third site serves as a safeguard that allows operations to continue without disruption.
This three-site redundancy ensures maximum uptime and minimizes the impact of unforeseen events, which further enhances the resilience of mission-critical applications and provides gold-standard protection.
Error Handling in a Metro Availability Configuration
In a multisite replication topology, error scenario handling is critical to ensure data integrity and continuity of operations. Here are some key error scenarios and how they can be handled:
Note on the setup:
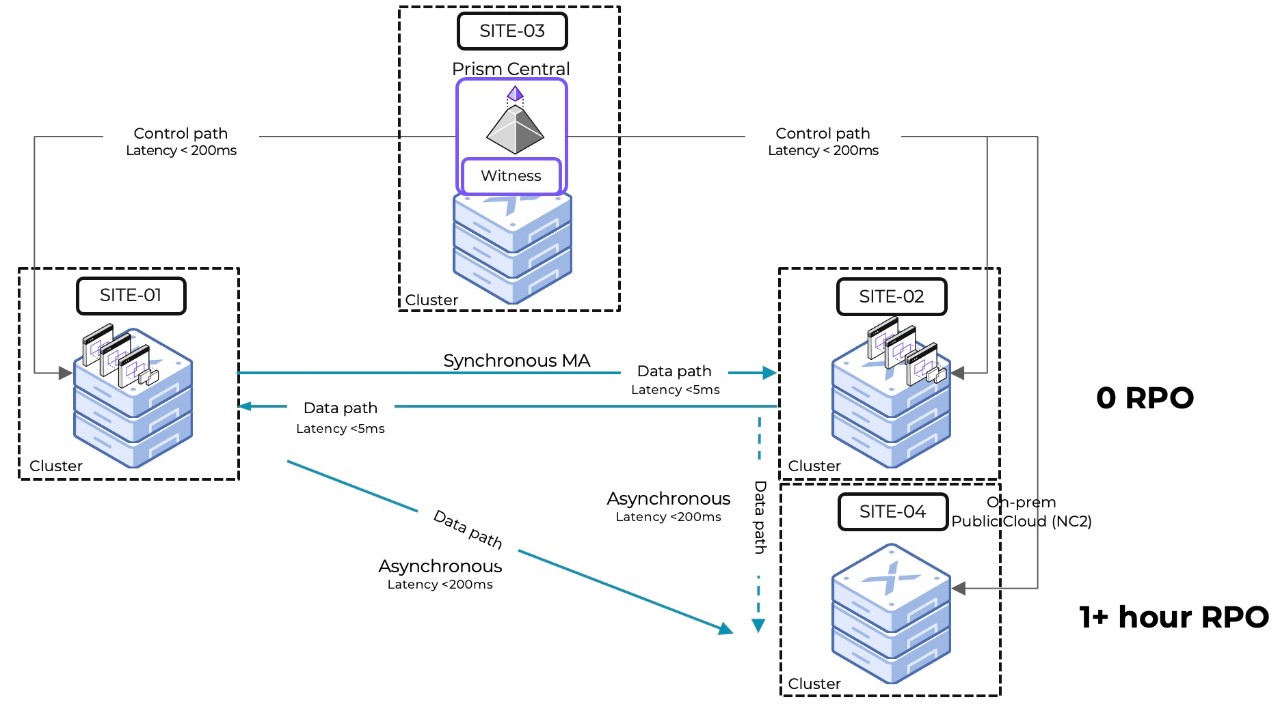
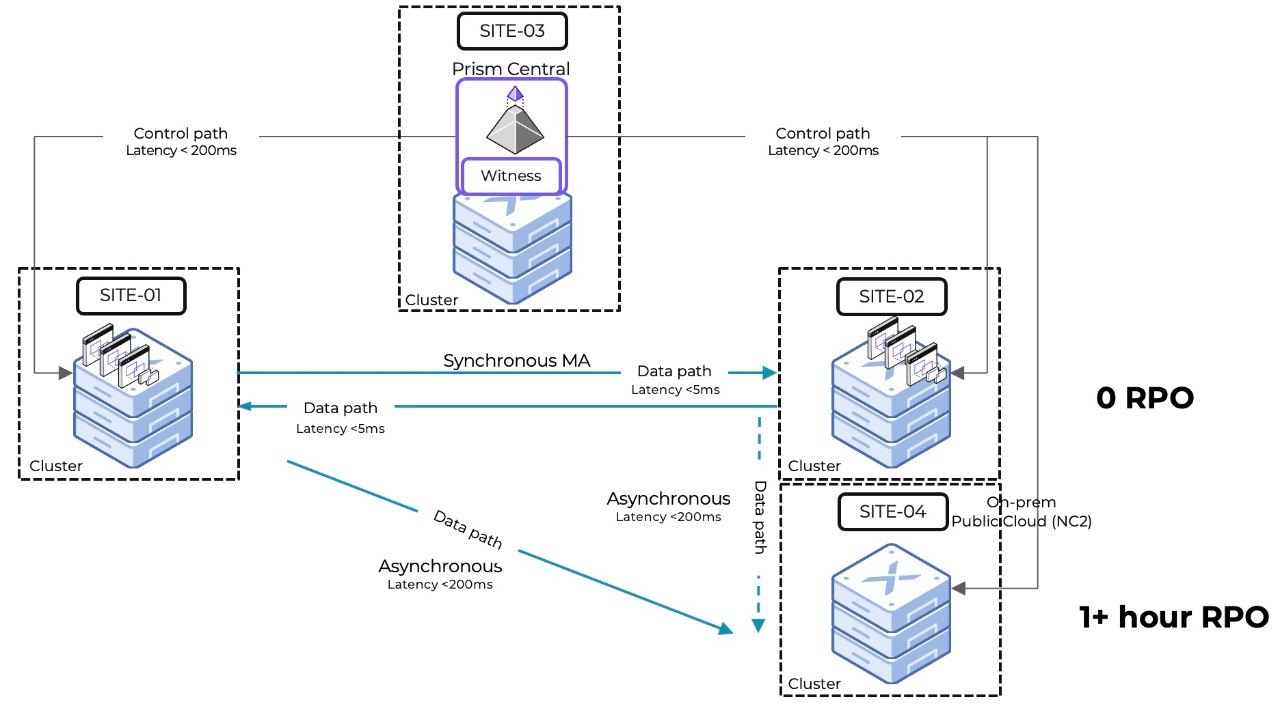
1. A Multisite site topology is considered between Site 01, Site 02, and Site 04.
a. Site 01 is the production site which hosts all applications and
b. Site 02 is the primary DR site (no live application) and
c. Site 04 is the secondary DR site (no live application)
This is the steady state
2. A single Prism Central (PC) management plane instance including Witness Service is hosted in Site 03.
3. Site 01 and Site 02 are configured for synchronous replication (0 RPO)
4. Site 01 and Site 04 are configured for asynchronous replication (1 hr RPO)
5. Site 02 and Site 04 are configured for asynchronous replication (1 hr RPO)
a. This replication path will be dormant in a steady state
6. Separate Recovery Plans are created between
a. Site 01 and Site 02
b. Site 01 and Site 03
Scenario #1: Production Site Failure

Recovery Procedure
Site 02 detects the unavailability of Site 01
Site 02 gets the lock on the witness
Site 02 initiates a UPFO
VMs are auto-cleaned up on Site 01 (production site)
Production VMs now move to Site 02
In addition, asynchronous replication of the same VMs kickstarts between Site 02 and Site 04
No administrative operations are necessary
Scenario #2: Primary DR Site Failure

Recovery Procedure
Site 01 detects the unavailability of Site 02
Site 01 gets the lock on the witness
Synchronous replications of VMs from Site 01 to Site 02 are paused
No administrative operations are necessary
Scenario #3: Network Partition Failure between Production and both DR Sites
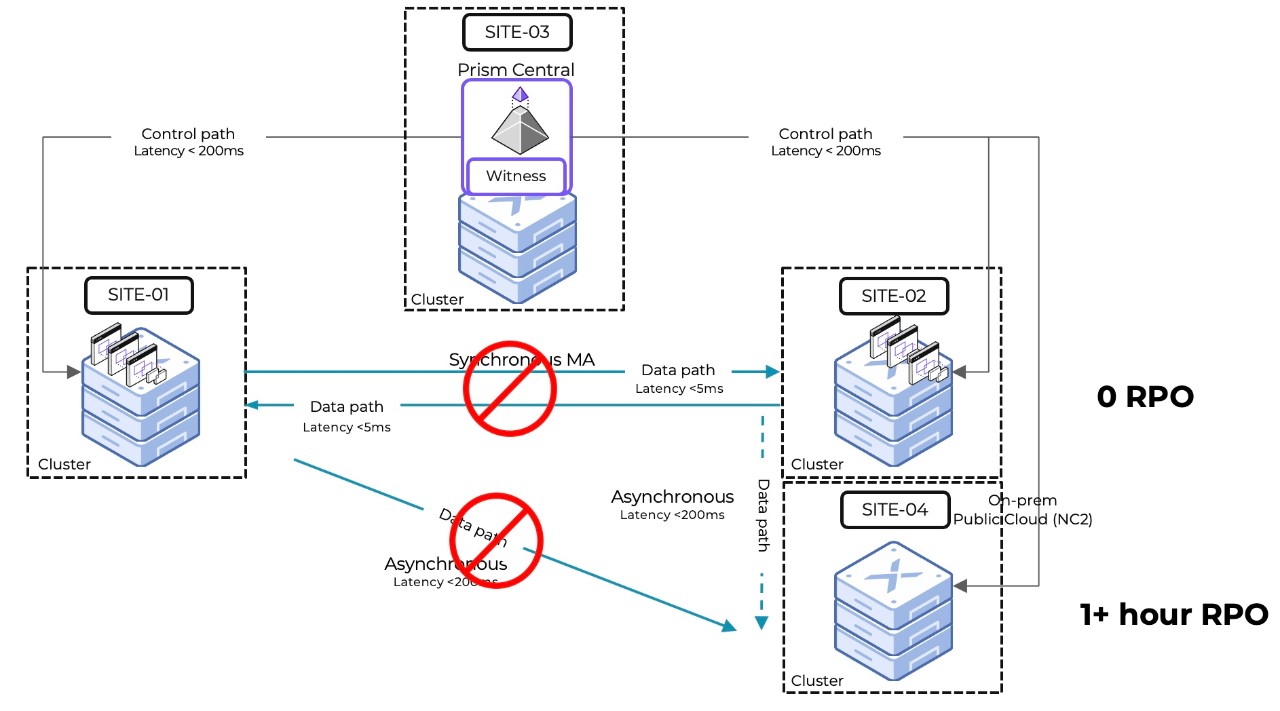
Recovery Procedure
Site 01 detects the unavailability of Site 02 and Site 03
Site 01 tries to acquire the lock on the witness
Site 02 tries to acquire the lock on the witness
Site 01 gets the local first and pauses the synchronous replications of VMs from Site 01 to Site 02
No administrative operations are necessary
Scenario #4: Double Site Failure – Production and Primary DR Site Failure
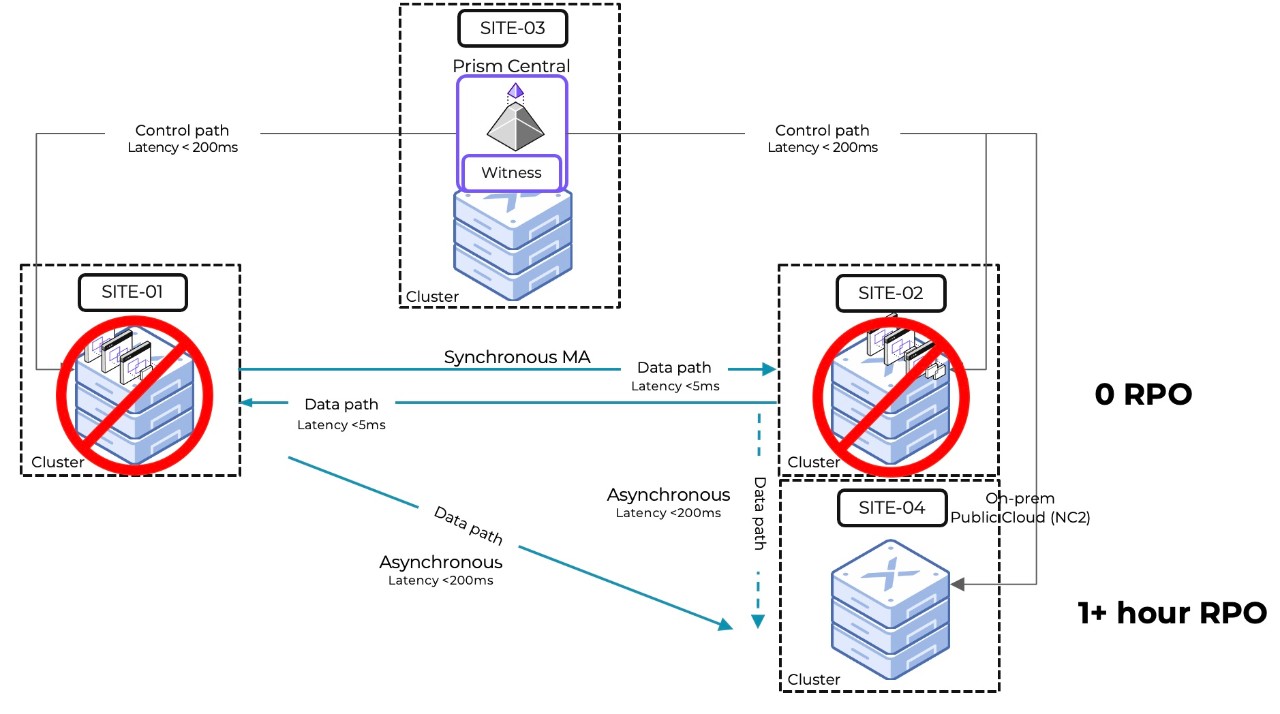
Recovery Procedure
Site 04 holds the data and can be made the production site
The user manually initiates PFO
Site 04 becomes the production site
Scenario #5: Prism Central Failure

Recovery Procedure
1. Site 03 hosting Prism Central and Witness Service is unavailable
a. Management and change configuration in Prism Central is not possible
2. Clusters in Site 01 and Site 02 trigger an alert
3. Synchronous Replication of VMs between Site 01 and Site 02 and between Site 02 and Site 04 continues
4. No administrative operations are necessary as replications are unaffected
Note: Administrators can initiate recovery using the Prism Central recovery process
5. When the Prism Central comes back online, Witness resumes automatically
6. No administrative operations are necessary
Conclusion
Protecting mission-critical applications is paramount to ensure sustained success and resilience in today's digital era. Enterprise organizations can mitigate risks, maintain customer trust and safeguard their reputation by prioritizing availability and compliance with regulations like the European Union Digital Operational Resilience Act (DORA).
Implementing solutions such as Metro Availability across multiple sites enhances resiliency and provides organizations with the confidence that their critical operations are shielded against potential disruptions. In a world where downtime is not an option, investing in the protection of mission-critical applications is an investment in the future success and longevity of your organization.
©2024 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s).
This post may contain express and implied forward-looking statements, including but not limited to statements regarding our plans and expectations relating to new product features and technology that are under development, the capabilities of such product features and technology, and our plans to release product features and technology in the future. Such statements are not historical facts and are instead based on our current expectations, estimates and beliefs. The accuracy of such statements involves risks and uncertainties and depends upon future events, including those that may be beyond our control, and actual results may differ materially and adversely from those anticipated or implied by such statements. Any forward-looking statements included herein speak only as of the date hereof and, except as required by law, we assume no obligation to update or otherwise revise any of such forward-looking statements to reflect subsequent events or circumstances. Any future product or product feature information is intended to outline general product directions and is not a commitment, promise, or legal obligation for Nutanix to deliver any functionality. This information should not be used when making a purchasing decision.