Service interruptions and data loss are two of the biggest threats to business continuity in the enterprise. Hardware failures, power loss, software bugs, human error and hackers, all contribute to the threats an organization faces to its operations, revenue and productivity.
In fact, Uptime Institute’s 2022 Outage Analysis Report found that 20% of all organizations faced a “severe” outage (involving financial loss, hit to their reputation or even loss of life) in the past three years. What’s more, 60% of all failures (not just the serious ones) cost the organization upwards of $100,000. And both these figures are on the rise, leading Uptime to predict that there will be at least 20 serious, high-profile outages every year in the foreseeable future.
“The lack of improvement in overall outage rates is partly the result of the immensity of recent investment in digital infrastructure, and all the associated complexity that operators face as they transition to hybrid, distributed architectures,” said Andy Lawrence, executive director of the Uptime Institute.
“In time, both the technology and operational practices will improve, but at present, outages remain a top concern for customers, investors, and regulators.”

A well-thought out plan for quick and effective disaster recovery is the need of the hour for continued data protection and uptime in any IT environment.
As with most other things, compared to on-prem datacenters, cloud has an arguable advantage – in both cost and complexity – in disaster recovery (DR). Common cloud technologies like SaaS have backup and DR options built in. For on-prem datacenters (and legacy environments), the cloud offers pay-as-you-go SaaS or IaaS DR solutions that can be scaled and customized to the unique needs of the business.
The Case for Cloud-Based Disaster Recovery
Cloud DR is a combination of tools, approaches and services that serve to back up data, applications and other resources to a dedicated public or private cloud and restore these to the production environment (whether cloud or on-prem) in the event of a disruption or disaster. In most cases, a Cloud DR solution is affordable, scalable, offered as-a-service, has a simple UI for control and management, and can be quickly deployed.
No surprise, then, that the global market for Disaster Recovery as a Service (DRaaS) is expected to grow from $8.8 billion at present to $23.5 billion by 2027 at a CAGR of over 21%, according to research from Markets and Markets.
“Cloud has changed the economics of disaster recovery. Some years back, only the biggest organizations could fully implement DR because it was so expensive to duplicate infrastructure and systems, even if it was through a third-party provider,” said Phil Goodwin, Research Director at IDC. “The pendulum has definitely swung towards disaster recovery in the cloud and DRaas.”
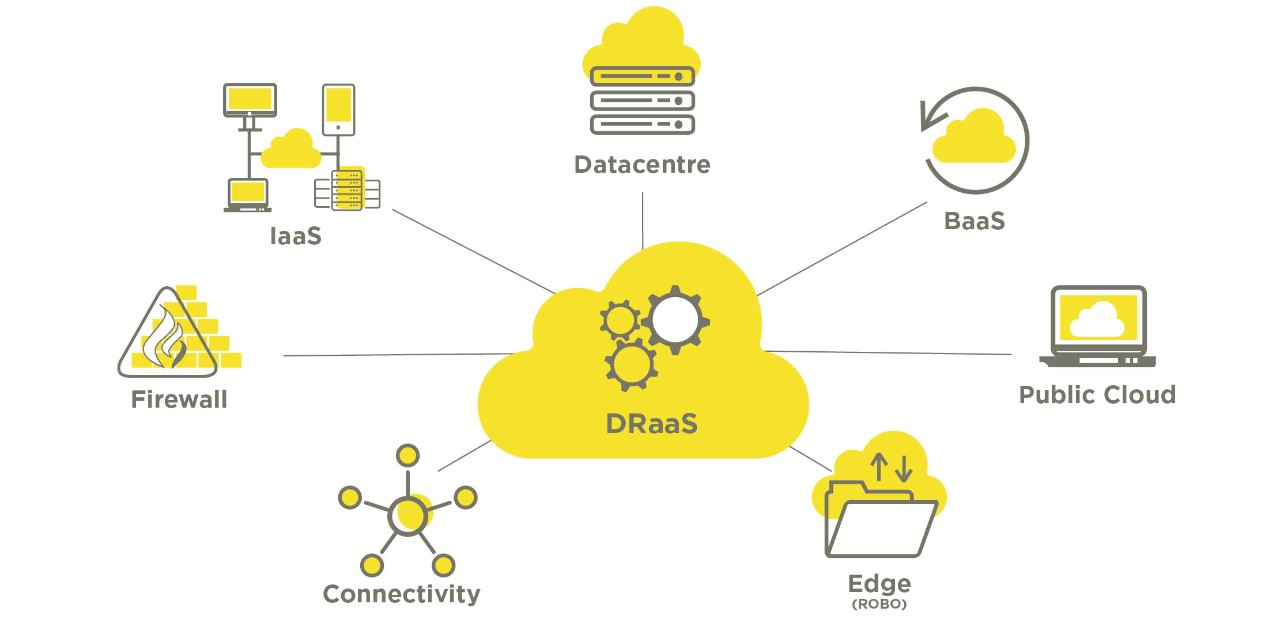
Source: M247
The TCO savings resulting from the on-demand model of the cloud could be the biggest plus for cloud-based DR. The organization doesn’t need to purchase or maintain hardware, or even have in-house specialists to stand by for a disaster. It is as simple as setting up regular backups and a subscription fee.
“One of cloud’s major advantages over in-house self-provision for DR is pay-for-use,” said Richard Blanford, CEO and Founder of Fordway. “As with all things cloud vs on-premise, it’s the decision between fixed costs and recurring costs for cloud or managed DR services.”
The Benefits of Cloud DR Vs. Traditional DR
What are the key advantages that influence the decision to move the DR (and by logical extension, backup) function to the cloud?
Pay-as-you-go:
Cloud DR services can start off with just a monthly recurring fee for resources used in storage and backups, while testing and actual restoration or recovery can be charged on a per-usage basis. This not only saves significant capital expenditure setting up and managing an off-site facility for DR but also prevents vendor lock-in by the colocation provider to a great extent.

Cloud providers don’t have the leeway to force organizations into long-term service agreements but they frequently offer a discount for the same, leaving the ball in the customer’s court. Most organizations have static DR needs and this model suits them better.
Redundancy without complexity:
Traditionally, enterprises set up secondary datacenters off-site to store redundant copies of data and applications, to which production workloads failed over. Such setups needed a dedicated facility to house the hardware as well as maintenance personnel. All equipment operated at the same capacity as the production environment. Lastly, considerable network infrastructure, a VPN or high-bandwidth internet was often needed to enable staff to connect remotely to the secondary datacenter.
With cloud DR, companies don’t need to build any physical infrastructure. They get access to their data along with the storage, platform and infrastructure resources to keep operations running smoothly – that too, within minutes using any device connected to the internet. Many times, remote end users already connected to a cloud environment will switch over seamlessly to the cloud DR infrastructure with the right DRaaS solution. Major providers tend to have advanced software-defined networking and edge-caching service that deliver quick, consistent performance. They also ensure 24*7 maintenance and upgradation of the DR infrastructure.

Cloud DR, by its very nature, also provides an additional layer of physical redundancy beyond a secondary datacenter. Data can be backed up or mirrored across multiple Points of Presence (PoPs) – or storage devices located in multiple geographical locations. This eliminates the “single point of failure” in the DR setup – even if one of the cloud provider’s datacenters fails, the client’s data is still available and accessible at all times.
Scalability:
Scalability is an inherent strength of the cloud. All storage, compute and network resources, apps and VMs can scale up and down within minutes according to the organization’s needs or policy changes. At no point during its growth does a company need to purchase additional hardware or expand its facilities just to ensure the continuity of operations.
While cloud DR clearly has significant benefits over its traditional datacenter counterpart, there are also significant gaps in deployment when it comes to security and compliance requirements. Most public cloud security concerns also apply to DRaaS.
“Digital infrastructure operators are still struggling to meet the high standards that customers expect and service level agreements demand – despite improving technologies and the industry’s strong investment in resiliency and downtime prevention,” said Lawrence.
This reinforces the need for an in-depth cloud DR strategy.
Creating a Cloud Disaster Recovery Plan
Building a comprehensive cloud DR plan follows the same steps and basic strategy as an off-site DR plan. The differences lie only in the cloud technologies (such as DRaaS) used in the execution.
Smart CIOs and admins insist on a Prevention, Preparedness, Response, Recovery (PPRR) plan for disaster recovery. Quickly, here’s what each means:
- Prevention – Proactively find and eliminate all possible vulnerabilities, risks and threats that could lead to a disaster.
- Preparedness – Anticipate and expect a disaster; do what it takes to prepare the organization for the event.
- Response – Create a line of action that stipulates what to do when disaster strikes in order to mitigate its impact.
- Recovery – Recoup and reclaim data and resources while bringing operations to their optimal level at the earliest.
The basic steps towards building a foolproof cloud DR plan include:
1. Understanding the infrastructure
It is essential to consider not just the cloud, but also the non-cloud components of the organization’s IT infrastructure. What are the hardware and software assets? Which workloads are critical and which ones are non-critical? What data is stored where? Who has access to what data and files? How much is it all worth?

The answers to these questions and an audit of all IT and digital assets will also help understand the risks to these assets in the event of a failure or disaster. Is personally identifiable information (PII) collected by any chance? What data is weakly encrypted? Are there any fire or flood risks?
2. Conducting a business impact analysis
This is where architects and administrators of both the IT and physical infrastructure come together to perform a detailed review of the environments and workflows, identify and evaluate potential risks as well as the organization’s tolerance of downtime.
Each company’s definition of downtime is different. Conducting a business impact analysis (BIA) will tell the organization how much loss (financial, operational and others) it can sustain before the disruption starts affecting business continuity.
Two key DR metrics are calculated in the process:
- Recovery Time Objective (RTO) – the maximum duration of time for which the IT resource or infrastructure can be inaccessible before the business faces significant loss
- Recovery Point Objective (RPO) – the datasets and maximum threshold of data within each dataset that can be lost or compromised at that point of time without causing a significant loss to business
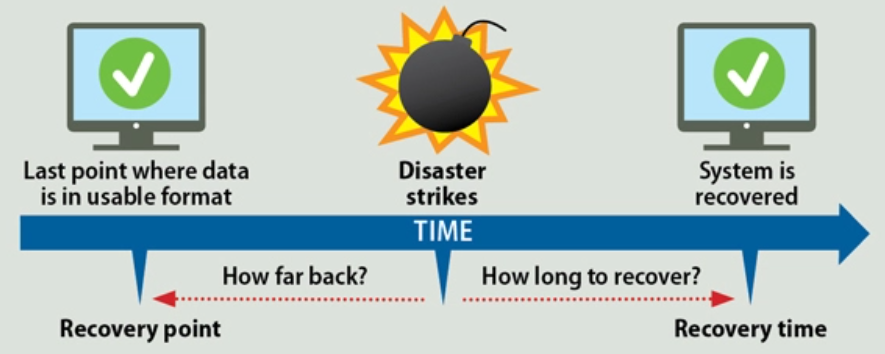
Source: Enterprise Storage Forum
This way, IT leaders also get a better idea of the mission-criticality of each workload and application, helping them focus more on important areas when disaster strikes. The BIA is a cost-benefit (or rather cost-loss) analysis of the downtime itself as well as the PPRR measures taken by the organization.
3. Choosing the right cloud vendor
DRaaS services are available in three flavors:
- Self-service: The customer plans and buys the right mix of backup and recovery services, configures, maintains and tests them at regular intervals, and invokes recovery measures when needed. This suits organizations that have skilled staff and experience running DR procedures.
- Assisted: DRaaS vendors or consultants can be hired to help plan and build the solution for the organization. Backups and restores (to a certain extent) is still managed in-house but additional customized support can be hired in special situations.
- Managed: DR operations are fully outsourced to a managed service provider (MSP) who creates and implements the DR strategy, chooses the cloud vendor and platform, and is responsible for recovery as per the RTO, RPO and other key metrics defined in the SLA.
However, choosing the right cloud vendor for DR involves much more than choosing the style of implementation. The speed and extent of recovery, scalability, reliability and security that they offer is of prime importance. Major cloud vendors price their solutions by the complexity and resources needed to meet the requirements of the solution. For example, AWS has four categories of DR solutions:
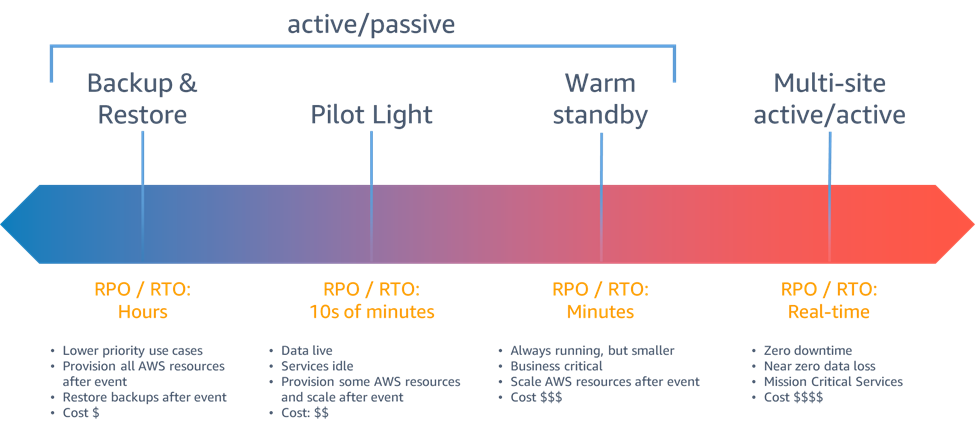
Source: AWS
Security, regulatory and compliance issues might prevent a lot of businesses from having DR in the public cloud. Control over organizational data is of paramount importance. Having said that, more providers now support classified data storage and offer more choices in geo-location.
The biggest risks for the organization are the cloud vendor going out of business (or taken over) or being legally prevented from operating in the region of interest.
4. Verification and testing
Testing whether the DR plan actually works is arguably the most critical factor affecting preparedness. Some key questions to ask are:
- Can all applications and platforms be installed from the DR cloud to the production environment? Is all software licensed?
- Can business-critical data be recovered and workloads regain functionality within the RTO and RPO thresholds?
- Does the recovered environment conform to the exact same security and compliance controls as the production environment?
Periodic test runs will help identify gaps in the DR strategy and plan for a corrective course of action. Wherever possible, there should be more than one always-operational path to recovery.
Protecting the Business
Goodwin predicts that high-availability cloud services that cater to applications as well as data will soon take over from infrastructure-centric DR. This can lead IT towards near-instant recovery if implemented correctly.
Cloud DR offers powerful customization options to CTOs and CIOs. However, the nature of the solution can differ wildly for different businesses. Ultimately, the organization knows best which data it needs to protect and to what extent.

Editor’s note: Learn more about Nutanix solutions for data disaster recovery.
Dipti Parmar is a marketing consultant and contributing writer to Nutanix. She’s a columnist for major tech and business publications such as IDG’s CIO.com, Adobe’s CMO.com, Entrepreneur Mag, and Inc. Follow Dipti on Twitter @dipTparmar or connect with her on LinkedIn for little specks of gold-dust-insights.
© 2022 Nutanix, Inc. All rights reserved. For additional legal information, please go here.
Related Articles
















