Data protection is simple to define: it is all about ensuring data isn’t accessed by unauthorized people. However, it is much more difficult to achieve. The concepts of both security and privacy are fully encompassed within the ambit of data protection. A single misconfigured device or a few keystrokes displayed on a publicly visible screen can bring an organization’s reputation down to its knees.
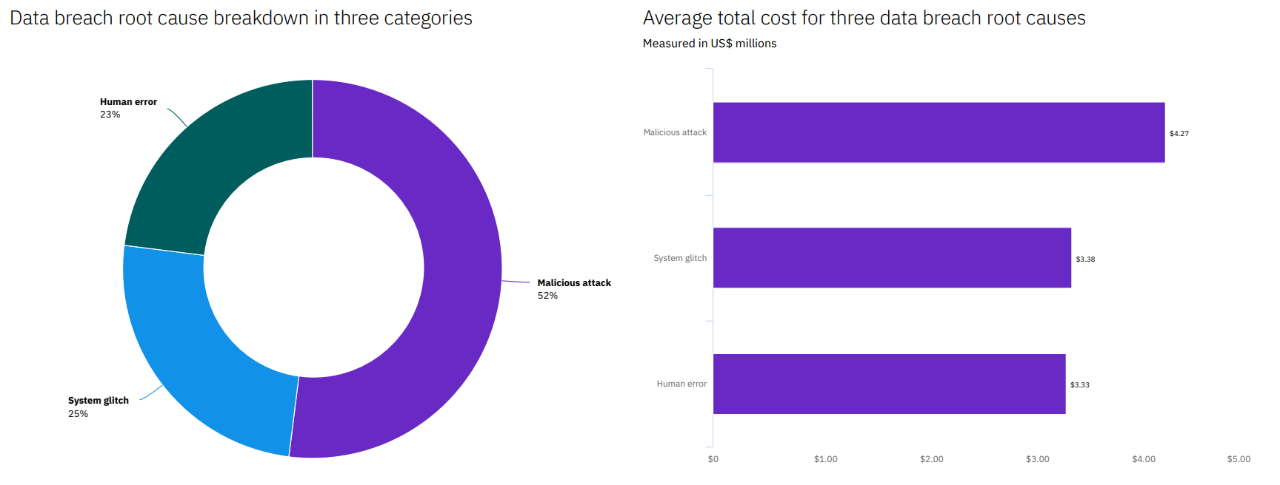
A study by the Ponemon Institute found that malicious attacks were the root cause of more than half of all data breaches in the enterprise while the average cost of fixing a data breach hovered around $4 million.
Traditionally, enterprises implemented strong perimeter defenses to thwart the perennially increasing number of breaches – which numbered 1,862 in 2021, up 68% from 2020 – and threats.
However, enterprise data is now being shared with and across vendors, customers, suppliers, business units, partner organizations, consultants, and remote employees, rendering the strongest perimeter security meaningless. The outsider is now an insider.
And so, enterprises need a complete end-to-end data protection strategy that secures data across applications, servers, networks, user devices, databases, and the cloud, right from the core to the edge – at all times, regardless of whether that data is at rest, in motion, or being used.
What Is “Enterprise” Data and What Data Needs to be Protected?
Before an organization even begins to secure its data across multiple locations, it must understand the data it has – the types, formats, and so on – as well as the variables that influence the access, storage, and transfer of that data.
Knowing which data is important enough to secure has long been a headache for enterprises. Traditionally, companies defined their own formats of data and files, which they deemed as important, and stored them in protected locations on centralized servers. However, this approach doesn’t scale today because data is constantly being created, shared, and accessed from multiple locations.

Identifying sensitive data is easier and more accurate today with ML algorithms, which automatically classify it as important as well as categorize it based on content. Instead of labeling files with a filename, these algorithms carry out “content-aware inspection,” which analyzes the file to determine the nature of its content – and decide if the content is important. This approach is far more scalable than its manual alternative.
There are also data discovery tools that save endless hours for admins by scouring the enterprise network for structured and unstructured data. They make use of contextual search technology and data mining capabilities to enable auto-classification and faster decision making.
Classification of Sensitive Data
Once all sensitive data is identified, IT admins need to determine the various confidentiality levels, decide where to store each unit of data, and decide which users or roles will have access to it (and to what extent).

Every block of data generated in the enterprise has its own set of risks and challenges. This warrants the need for data classification so that IT teams know exactly how to handle each piece of data.
While most organizations have their own custom categories of data, the four classes into which sensitive data is typically grouped are:
- Public: Freely available information that anyone inside or outside the organization can access anytime. Examples include contact information, marketing materials, and prices of goods and services.
- Internal: Data that isn’t meant for the public’s or competitors’ eyes but is shared freely within the organization. Examples include organizational charts and sales playbooks.
- Confidential: Sensitive data that can negatively impact the organization if shared with unauthorized people. Examples include supply contracts and salaries of employees.
- Restricted: Highly sensitive corporate data that brings legal, financial, reputational, or regulatory risk to the organization if leaked. Examples include customers’ medical data and credit card details.
While sensitive data comes in myriad shapes and sizes, the obvious ones are Personally Identifiable Information (PII), Personal Health Information (PHI), Payment Card Industry Data Security Standard (PCI DSS), biometric data, and consumer behavior data. There are also certain industries – such as healthcare, finance, higher education, government, ecommerce, and telecommunications – where data is more regulated than others.
Which Factors Affect Data Security?
When done right, a security policy protects against data loss and unauthorized access across all devices, systems, and networks. It is delivered, monitored, and managed via a combination of standardized processes and technologies such as firewalls, antivirus programs, and other tools. These standards and processes vary according to the use and criticality of data as well as the regulations that bind it.
“Security teams have to not only understand a multitude of technologies that operate across disparate substrates and platforms but also understand how those technologies can be exploited and how to protect them,” said Sebastian Goodwin, CISO at Nutanix. “With unique vulnerabilities in each platform, it’s a constant challenge to prioritize and mitigate risk.”

Security admins need to be aware of and understand the evolution in data storage and usage from the perspective of both technology and nature of work. Some of these changes that directly affect data security are:
Big data: The amount of data generated every day is huge. IDC has projected that the size of the global datasphere will reach 175 ZB by 2025.
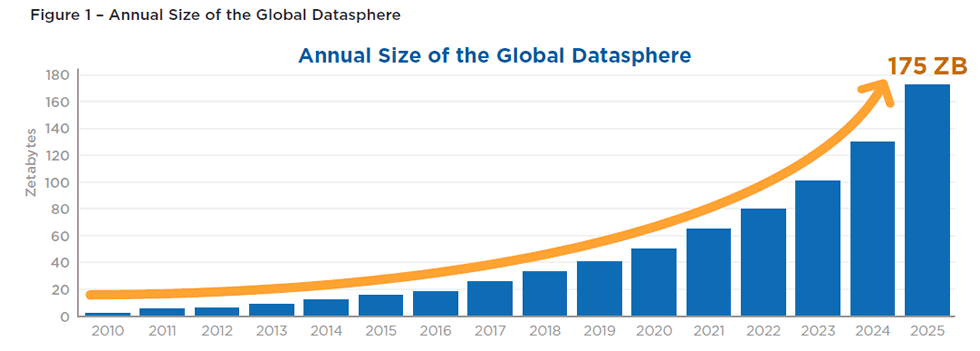
And yet, much of this data isn’t useful or used on time. Or can’t be analyzed cost-effectively.
Further, this data comes in a variety of different formats that can’t easily be categorized or processed. According to research by MIT, 80% to 90% of all data today is unstructured – in the form of audio/video-text combinations, server logs, social media posts, and so on.
“There is just too much data to successfully identify within the typical enterprise. Let me tell you from experience, unless it is data that is obviously classified as personal health information, or card-payment information, then it is difficult, near impossible, for organizations (except maybe the military) to properly classify and rank their data,” wrote Rob Juncker, CTO of Code42 on Threatpost.
End User Computing (EUC): The number and variety of devices that connect to the enterprise network (individually and through the internet) have risen exponentially. They include IoT devices, wearables, sensors, and industrial robots.
This means enterprise data is no longer a static entity residing only in well-defined, controlled locations. It spans each and every device and application that users access. Today, applications run on VMs, desktops, mobile phones, or hybrid clouds. These apps are constantly generating data that is in perpetual motion – from the user’s screen to the enterprise data center or cloud and back – across multiple environments and geographical locations.
All of these make the job of securing data increasingly complex, although enterprises are making inroads in simplifying things with data virtualization.
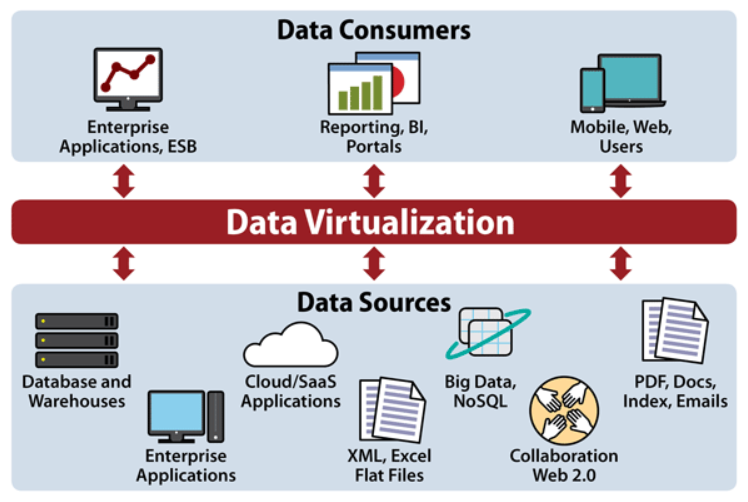
Hybrid environments: IT infrastructure is increasingly converged and moving from data centers to a cloud-based environment. And a hybrid cloud at that for the enterprise. This makes security (the public cloud parts, at least) a shared responsibility between vendors and customers.
“The public cloud doesn't secure your applications for you,” said Mike Wronski, former Director of Product Marketing at Nutanix. “The providers secure their infrastructure, but they don't ensure that the services are implemented securely. They leave that up to the customer.”
Remote work: The COVID-19 pandemic necessitated an overnight shift to remote work and work-from-home for most, if not all, companies. Many enterprises were left struggling to enable their employees to access business-critical apps and files from home. Even before they could assess the risks and implement adequate security procedures, WFH became the norm.
“There was a rapid shift to everyone working remotely, and not all companies were set up to work that way. Some had to make hasty moves to let people access systems and applications from home,” said Goodwin.
“The problem is we can’t monitor what employees are actually doing on their personal networks. We can just identify suspicious addresses and malware and take measures to keep them from compromising the IT infrastructure.”

Bearing all these tremendous shifts in mind, CIOs, CTOs, CISOs, and security admins need to take some far-reaching steps to protect their companies’ and their customers’ data at all times.
What Security Measures Can Enterprises Take?
No two security threats are alike. IT leaders need to be aware of different kinds of threats that apply to their work environment and make sure their systems are being vigilantly monitored for intrusions.
Educate employees on security best practices: Every employee needs to understand how vital data is to the business and the consequences that follow if it is compromised. Make sure employees pay attention to where emails are coming from, open emails only from trusted senders, and don’t click on links or attachments that they’re unsure of. The same goes for using a browser – all employees should be able to recognize warning signs on web pages and tell a dodgy site from a trustworthy one.
Password management warrants special attention; easy-to-break and shared passwords are still the number one cause of worry for enterprises. “Passwords are obsolete at this point. Ten years ago, it was time-consuming and processor-intensive to create a list of a billion passwords to hack a user account. But now it’s a trivial task,” said Goodwin.
“You need multifactor authentication, which requires a combination of biometrics, phone authentication, hardware or software tokens, or other verification methods,” he explained.
A periodic refresher course for everyone in security basics and risks will go a long way in keeping threats at bay.
Implement granular control: Security experts recommend deploying a zero trust model, which involves giving users and applications bare-minimum access to the resources they need to function effectively. This entails microsegmentation of networks and building very specific policies around servers, VMs, platforms, applications, and services that adopt a “least privileged” approach to data that is classified as sensitive.

Implementing Identity and Access Management (IAM) best practices coupled with Multi-Factor Authentication (MFA) is key to enforcing zero trust security in the enterprise.
Encrypt all data: Encryption is the process of obfuscating data using an algorithm that scrambles data. Only users with the right key (or access level) can decrypt the data and view or process it. This ensures the security of data at rest as well as in transit. Encryption comes in four flavors:
- Network level: Protocols such as SSL and IPsec are used to ensure that all communications within the enterprise network as well as with external networks are encrypted.
- Application level: Data such as financial, health, and consumer records, which is generated, processed, and authorized at the application tier, can be encrypted within the application logic using standard application cryptographic APIs. This protects data in case of lateral hacking of applications or databases.
- Database level: Data is secured at the time of read/write at the field level within a database table, eliminating the need for application level encryption. Performance is a serious consideration here, so database level encryption must be limited to sensitive fields or offloaded to hardware.
- Storage level: This is the most intuitive way to safeguard against data theft. Data is encrypted at the file (NAS/DAS) or block (SAN) level, directly protecting files and directories residing on HDD, SSD, and other media.
Securing Data Inside Out
Data is the currency that drives every organization, large or small. Nothing is more important for an enterprise than protecting its data against loss, corruption, and theft.
“The number of breaches in 2021 was alarming. Many of the cyberattacks committed were highly sophisticated and complex, requiring aggressive defenses to prevent them. There is no reason to believe the level of data compromises will suddenly decline in 2022,” warned Eva Velasquez, President and CEO of the Identity Theft Resource Center.
Concurrent connections between customers, vendors, partners, and a mobile workforce have blurred the lines between insiders and outsiders, rendering perimeter defenses ineffective. A solid data protection strategy extends from the core – where key data repositories reside – to the edges – where data is gathered and used. Enterprises need to take this spread into account at all times, whether they’re in the middle of consolidation, transition, or transformation.

Dipti Parmar is a marketing consultant and contributing writer to Nutanix. She’s a columnist for major tech and business publications such as IDG’s CIO.com, Adobe’s CMO.com, Entrepreneur Mag, and Inc. Follow Dipti on Twitter @dipTparmar or connect with her on LinkedIn for little specks of gold-dust-insights.
© 2022 Nutanix, Inc. All rights reserved. For additional legal information, please go here.
Related Articles
















