Bad data. It’s incomplete, incorrect, poorly segmented or miscategorized information. It prevents companies from carrying out operations, delivering good customer service and implementing their strategies. It can wreak havoc. An article from the MIT Sloan Management Review estimated that bad data costs companies as much as 15% to 25% of their revenue.
Eliminating the costs of gathering, storing, accessing, sorting and analyzing data is not too difficult, according to the MIT report. Paying attention to how information is collected and processed in the organization goes a long way towards streamlining production, sales and customer service.
Getting high-quality data, running it through appropriate analytics tools and applying the resultant insights forms the core of the digital transformation across enterprises and small-to-medium businesses (SMBs) today.
In today’s big data-centric world, companies need to manage large amounts of data generated by consumer-facing applications and processes. They must also continuously upgrade technology, devices and software. They should maintain their IT infrastructure at a low total cost of ownership (TCO) in order to remain competitive, reach new markets, improve customer service times and make sure their products offer value for money.
There are proven ways to extract business value from data without letting the costs get out of hand.
Virtualize Data on the Cloud – and Bill It (Internally) Like Amazon
An IDC report found that businesses and consumers are turning to the cloud for fast, ubiquitous access to their data. They’re even fine with lower storage capacity on endpoint devices, which are nevertheless becoming increasingly intelligent and connected.
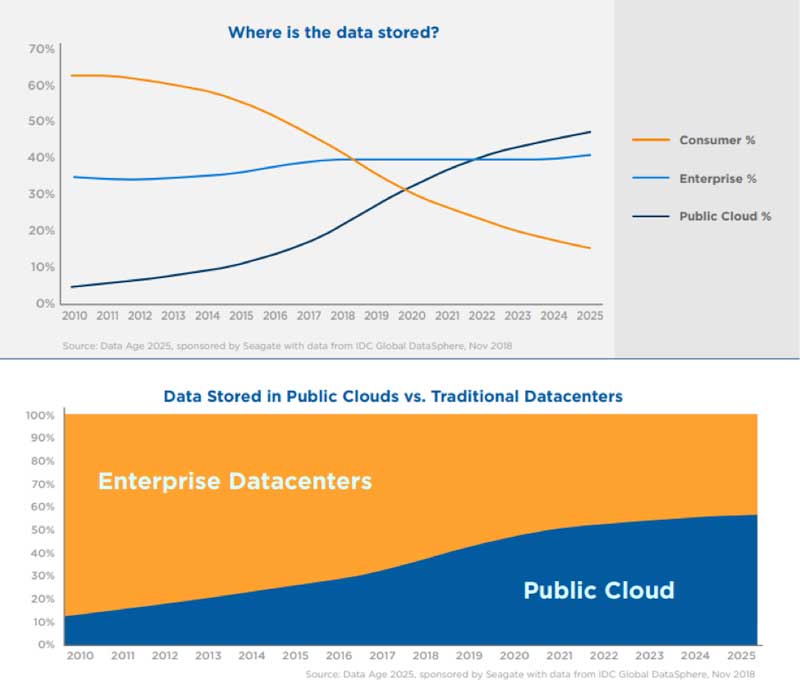
Source: Seagate Data Age 2025
Many companies are already using private, public and hybrid cloud environments for data storage and computing requirements. However, they struggle to manage CAPEX and OPEX when it comes to server and resource utilization, according to Enterprise Management Associates. Development and data science teams alike order rack-mounted servers and hardware independently according to their workloads, which end up being used at only 10% to 20% of their capacity. IT is then saddled with maintenance and monitoring, leading to increased costs across departments.
The solution, especially with big data, is to bill it like Amazon. Amazon’s EC2/S3 runs Hadoop jobs in a 100% virtualized form, in a virtual machine (VM) container. VMs can be added or removed programmatically. This enables true economies of scale because different jobs are sandboxed in their own VM and yet run simultaneously.
The pay-per-use model is common to all public cloud services. When an equivalent of this model is adapted and adopted for budgeting resources in private or hybrid on-premise environments, it will bring greater cost and resource efficiencies because users will be forced to optimize hardware and VMs for system utilization.
This is why storage and backup of data in the cloud is more of a business than a tech consideration. In multicloud and hybrid environments, the cloud vendors and managed service providers (MSPs) the organization works with also become critical cogs in the process.
Deploy a Hyperconverged Infrastructure (HCI)
When dealing with big data, virtualization presents a lot of cost-saving options by eliminating OS-based redundancies. However, there are limited options for storage virtualization in the market today. Few solutions focus on separating the storage logic from the data analytics logic.
"When dealing with big data, virtualization presents cost-saving options by abstracting hardware and OS management-related complexities, said Somnath Mazumdar, a researcher with Copenhagen Business Schools' Department of Digitalization.
“However, in the market today, there are limited options (such as software-defined storage) for managing multiple software storage-related complexities as well as seamlessly combining different legacy hardware storage technologies."
Virtualization is sorely missing a big data component because underneath the virtualized and converged servers in enterprise data centers, system management applications continue to run on embedded SQL databases. These databases are a pain to manage, debug and scale. As a result, virtualization has been done in by legacy storage networking systems that are remnants of archaic physical environments.
While SQL and Oracle databases have been the backbone of traditional enterprise datasets, the Apache Hadoop platform and the NoSQL database system have emerged as new, cost and resource-effective tools for storing, organizing and managing large volumes of unstructured data (which is less expensive to collect).
[Related technology: Turn Your Database into a Service with Nutanix Era]
These tools help bring cloud storage and computing closer to each other, given the right infrastructure. Hyperconvergence takes the complexity out of managing enterprise cloud systems. Hyper-converged infrastructure (HCI) combines common datacenter hardware using locally attached storage resources with intelligent software to create flexible building blocks that replace legacy infrastructure consisting of separate servers, storage networks, and storage arrays. HCI solutions also allow companies to simplify and accelerate big data deployments with easily repeatable application deployment blueprints.
Other data-specific benefits include:
Data locality – Data used by each VM is preferentially kept on local storage on the node on which the VM is running.
Auto-tiering – Hot data is stored preferentially in solid-state flash drives (SSDs) while cold data is stored in the hard disk drive (HDD) tier. Data is automatically moved between tiers and even archived from the cold tier based on access patterns for optimal performance.
Auto-tuning – Both random and sequential I/O is taken care of without the need for constant performance tuning, even when multiple workloads are running simultaneously.
Auto-leveling – Data from any VM can use storage on other nodes when needed, balancing storage, eliminating the possibility of running out of storage space, and simplifying data management.
Easier management – Enables the use of distributed software such as Splunk, which captures, indexes, and correlates machine-generated data.
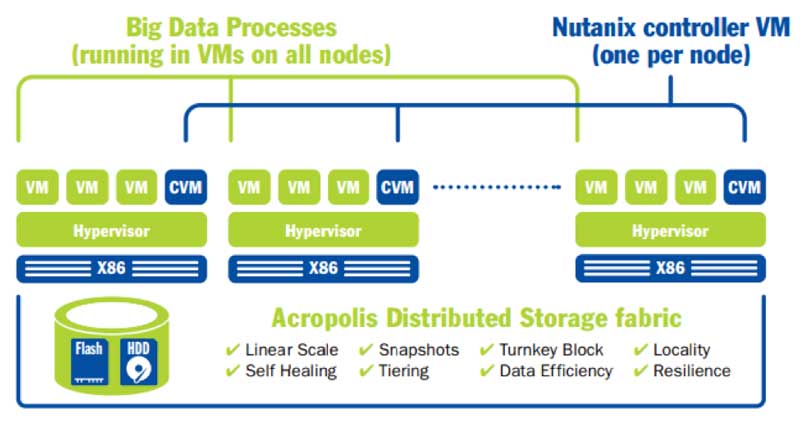
Source: Nutanix Definitive Guide to Big Data
Make Organizational Processes and Strategies Data-First
In the Information Age, it’s safe to state that every business is an “information business.” NewVantage’s 2018 Annual Big Data Executive Survey found that 97% of Fortune 1000 companies continue to invest in big data with a goal of improving analytics for better decision making.
“This continuing rise in the importance and challenges of Big Data is one of the most important features of the contemporary economy and society,” said Thomas H. Davenport, a thought-leader in data and analytics, and author of Competing on Analytics.
“The key to success is to determine how your firm should respond and then to move ahead to execute the needed changes in a systematic and effective fashion.”
Organizations are putting data to work for the most cost-effective outcomes for their industry by:
Preparing to adapt – The organization has to be ready to undergo a fundamental change in the way it uses and applies data. The very structure and culture of the organization may change according to technological or even regulatory requirements.
Recruiting and partnering better – It's necessary to bring on board talent with the essential data analysis skills. Also, work with vendors who use data efficiently.
Making iterative improvements – Identify data that can be immediately put to use, let processes run their course with the new, improved data, and then make organizational changes based on learnings.
Focusing on speed and agility – Implement technologies that enable quicker extraction of information with simpler methods. This is critical for innovation as well as marketing. Encourage experimentation and budget for trial and error based on insights from data.
Data is every organization's primary strategic resource. Businesses need to keep building “data assets” to strengthen and scale their position in the market vis-à-vis competition. This will only happen if executive management puts in place a budget to improve data readiness and a strategy to make efficient use of data and analytics in decision-making.

Featured Image: Pixabay
Dipti Parmar is a contributing writer. She has written for CIO.com, Entrepreneur, CMO.com and Inc. magazine. Follow her on Twitter @dipTparmar.
© 2020 Nutanix, Inc. All rights reserved. For additional legal information, please go here.
Related Articles









