Over four in five IT leaders agree that a hybrid, multicloud environment is the ideal operational model to keep IT infrastructure running smoothly and help mitigate challenges, per the 2025 Nutanix Enterprise Cloud Index. Improving overall hybrid cloud performance and achieving operational and strategic goals requires application resiliency.
Application mobility, interoperability, and control should be priorities for every organization. Building resiliency into business-critical applications ensures that IT teams can quickly identify and resolve typical issues that plague application performance in the cloud while continuing to drive business outcomes.
What Is Application Resiliency, and Why Is It Important?
The high availability of applications and platforms is a significant cloud benefit. When an application successfully leverages the fundamental capabilities of the cloud or hyperconverged infrastructure to deliver uninterrupted services, it fulfills the promise of the cloud.

Capabilities such as automated and continuous monitoring, clustering, load balancing, and automatic failover should function at all times and under all conditions. Application resiliency is the ability of the application to maintain a minimum viable or acceptable level of service in the face of various disruptions and challenges to usual or optimal operating conditions.


In the early days of business computing, IT admins struggled to ensure system stability because of frequent server crashes. Hardware and software components like servers and databases were expected to fail. Primary or secondary configuration structures, depth, and redundancy were the only ways to reach resiliency. Availability and system uptime were achieved by distributing business-critical applications across servers in different locations and balancing the load among them. Servers, workstations, terminals, OSes, and databases were rebooted periodically to ensure maximum availability.

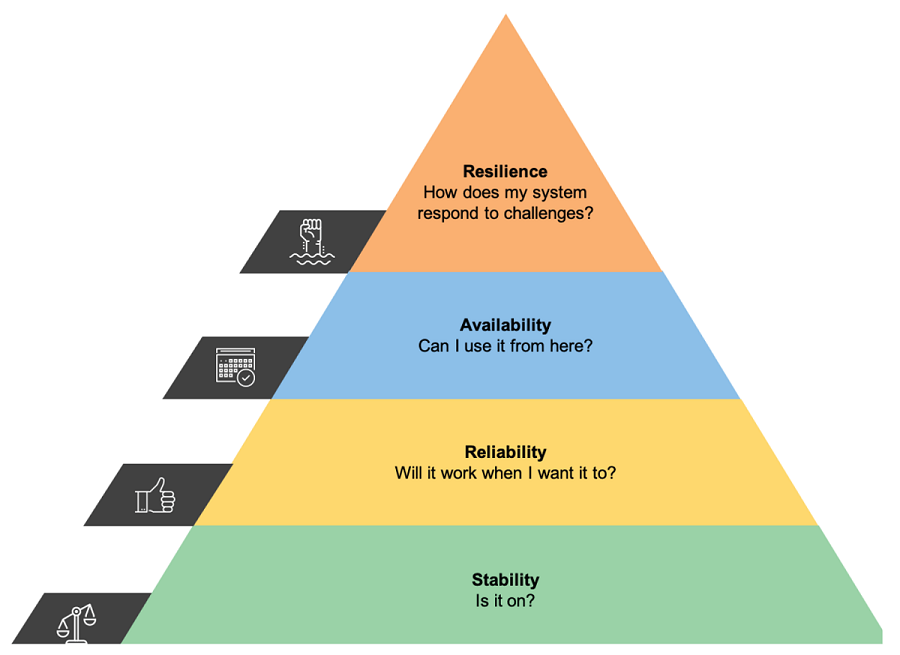
While “reliability” requires a system to function as expected, “resilience” builds on the expectation that things will go wrong. The application is structured and tested to adapt to and correct unexpected or “wrong” events, moving from stability to availability to reliability to resilience.
Resiliency is not just about avoiding failure.
Source: Infosys
It also involves accepting the failure and building and automating the next steps so the application can respond to the event and return to a fully functioning or optimal state as quickly as possible.
Benefits of Resilient Applications
A fully resilient application can adapt to unforeseen events that disrupt the IT environment and automatically initiate fault recovery or graceful degradation processes. It continues to function normally or at near-normal levels despite the failure of core system components.
The extent of application resiliency in the cloud and its relative importance to business continuity depends on various goals, requirements, and constraints. These factors are influenced by the type of workload, the role of the users, and the scale and technical capabilities of the organization.

Three different kinds of drivers motivate an IT organization to build resilient apps:
Business drivers:
Cost savings on IT infrastructure, deployment, and operations
Delivering the best user experience and minimal app downtime
Meeting user demands at times of peak and extended usage
Maximum quality of service and availability
Retaining user trust
Flexibility to adapt to changing market demands
Development drivers:
Maximizing time spent on adding new features
Reducing troubleshooting time
Following the latest industry practices and trends in development
Operations drivers:
Optimal resource consumption
Reducing the frequency and impact of disruptions and failures
Ability to recover quickly from failures
Increasing automation
Resilient applications serve to improve system availability, which is the primary indicator of the health of the IT deployment.
However, organizations transitioning to a hybrid IT infrastructure are in various stages of their journey. Moving to the hybrid cloud involves significant challenges in interconnectivity, integration, and data protection and management compared to traditional IT models. Many organizations struggle to adapt legacy processes, resources, and capabilities to hybrid, multicloud environments, which now often include remote or hybrid work.

A study by 451 Research in June 2020 found that most organizations seriously lacked business continuity planning, cloud management strategy, and data and application resiliency. More than 55% of respondents were using a mix of on- and off-premises cloud or hosted resources with various levels of interoperability and an ad hoc approach. Without the right hybrid cloud strategy, companies might experience additional operational overhead while running separate environments.
Five years later, new technology, generative AI tools, and more diligent threat actors are introducing additional focus areas. IDC’s FutureScape 2025 report highlights the need to document and optimize AI applications so they align with business goals. This year, about two-thirds of AI spending will come from enterprises enabling AI within their operations.
Cyber resilience is also more critical than ever, though businesses are still immature in building a comprehensive plan. PwC found that only 2% of CISOs have implemented cyber resilience in all 12 measured areas across people, processes, and technology. Establishing a resilience team, regularly assessing gaps, and adjusting strategies through proactive risk and scenario planning will help organizations stay ahead.
Factors That Affect Application Resiliency
Application resiliency mandates a deliberate hybrid cloud strategy and planning at all levels of the architecture. How the IT infrastructure and network are laid out, plus the design of data and storage systems, are key influences.
“Access to shared infrastructure, data, and application resources in the cloud play a critical role in helping organizations navigate disruptions,” said Rick Villars, Group VP, Worldwide Research at IDC.


“In the coming years, enterprises’ ability to govern a growing portfolio of cloud services will be the foundation for introducing greater automation into business and IT processes while also becoming more digitally resilient.”
Some constraints limit an application’s ability to scale and deliver high performance. Developers, product designers, and system architects must minimize these constraints:
Hardware and software dependencies
Dependencies on other apps
Licensing restrictions
Lack of skills in development teams
Organizational resistance to change
There are also cloud-specific challenges in planning for application resiliency. Cloud systems favor scaling “out” to a larger number of nodes, compared to scaling “up” to a bigger, more powerful node in traditional IT architecture. Developers can code in a graceful degradation of the application in case of a node failure. They can avoid large service buys and provision resources by adding capacity in smaller units. In an on-premises private cloud deployment, VMs and load balancers may provide enough support.

However, when an infrastructure spans multiple geographic regions, things are complicated by requirements such as DNS session management, request routing, and persistent storage. Specific implementation and vendor support vary significantly in such scenarios.
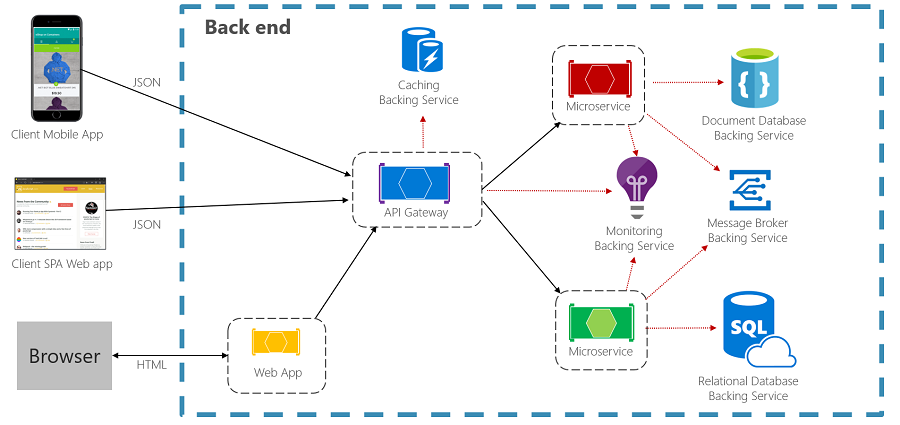
Further, cloud-native applications operate over a distributed architecture. Executing the business logic across multiple pieces of hardware requires detailed planning around state management, load balancing, and latency correction.
Source: Microsoft
In cloud architecture, each of the microservices and cloud-based backing services that an application uses executes in a separate process and communicates via network-based calls. Multiple challenges to application resiliency can arise in this scenario, such as hardware failure, network latency, transient faults, crashed host processes, and overloaded microservices.
While the underlying cloud platform has built-in protection to detect and mitigate many of these issues, applications must be designed to handle these events automatically and dynamically.
How to Build Application Resiliency in the Cloud
Cloud infrastructure and application development are two fields that are perennially evolving. Best practices to build and optimize resilient applications in the cloud include:
1. Leverage Infrastructure as Code (IaC)
IaC allows admins to configure the infrastructure and handle its provisioning similarly to application code. The configuration and provisioning logic is stored in a code repository with source control, enabling versioning, discovery, and auditing. Architects, admins, and developers can set up CI/CD pipelines with automatic testing and deployment of changes.
Automated infrastructure provisioning minimizes human error in configuration and provides consistent environments that can be replicated, increasing app resiliency.
2. Use Physically Distributed Resources
When deploying cloud workloads across geographic regions, the application is more likely to experience latency and availability problems. Deploying the app to multiple areas within a cloud provides redundancy and enables it to withstand service disruptions in a particular region.
3. Implement Cloud Native App Development
As dynamic AI workloads become more commonplace, combining hybrid multicloud and cloud-native systems enables IT teams to quickly and efficiently implement and monitor apps and data in various IT environments. Tobi Knaup, general manager for Cloud Native at Nutanix, believes this will be the new industry standard.
“Cloud native really is a concept that describes how to build and run modern applications,” Knaup told The Forecast.
“Those applications are typically microservice-oriented, they run in containers, and they’re dynamically managed.”
4. Monitor the Whole IT Environment
Understanding an application's behavior and how it interacts with other hybrid cloud components helps identify the most critical metrics for performance monitoring. Tracking metrics at all levels—infrastructure, app, and service—increases the chances of unearthing potential issues before they cause disruption or outage, diagnosing the cause, and resolving the issue.
Infrastructure-level metrics may include CPU load, I/O rate, and memory usage. They indicate whether hardware is overloaded or functioning as expected. App-level metrics provide information like the time it takes to execute a query or perform a sequence of service calls. These metrics capture a snapshot of the application’s conditions and can reveal issues in the workflow. Developers have complete control over defining and monitoring these metrics. Service-level metrics help watch for latency and errors in the interactions between various services and components the app uses.
Finally, end-to-end, or “black box” monitoring, provides a holistic picture of the app’s health by analyzing its externally visible behavior just as users perceive it. The speed and ease with which users perform core tasks and actions within defined thresholds reflect the application's availability.
5. Consider Managed Services
Another practice that improves overall system availability in the hybrid cloud is using managed services for certain parts of the application stack. Doing so saves in-house admins the trouble of installing, operating, managing, and supporting services or platforms that are central to the smooth functioning of the workload.
There could be an area where they lack expertise or an off-the-shelf solution, like a MySQL database. The availability of this resource is guaranteed by the managed service provider or cloud service vendor; the onus of managing data replication and backups falls on them.
Application Resiliency Considerations
The rising popularity of cloud native applications, increased reliance on AI tools, and adoption of Infrastructure as a Service (IaaS) in the enterprise have set new benchmarks and best practices for application resiliency. More workloads are shifting to the hybrid cloud. Thin provisioning and auto-scaling are enabling rapid deployment of new applications. Newer and better technologies are simplifying active/active setups, secondary and tertiary disaster recovery environments in the cloud, and multi-region load balancing.


As the divide between applications, platforms, and infrastructure continues to blur, designing apps for resiliency will require in-depth planning and collaboration between IT and operations.
“The reality of enterprise IT now is that it's a multicloud world,” said Steve McDowell, chief analyst at NAND Research.
“Workloads can live anywhere and often do, and they ping pong back and forth.”
McDowell also noted the technology-driven advantages organizations have today.
“What the software-defined world has done is enable companies to start and scale very quickly. It allows you to deploy new applications rapidly and enables businesses to leverage technology to provide more tailored services for customers.”

This is an updated version of the article originally published on May 19, 2022.
Featured image by Pxfuel
Dipti Parmar is a marketing consultant and contributing writer to Nutanix. She’s a columnist for major tech and business publications such as IDG’s CIO.com, Adobe’s CMO.com, Entrepreneur Mag, and Inc. Follow Dipti on Twitter @dipTparmar or connect with her on LinkedIn for little specks of gold-dust-insights.
© 2025 Nutanix, Inc. All rights reserved. For additional information and important legal disclaimers, please go here.
Related Articles
















