Scaling, in the context of IT infrastructure, is like superman – always going up, up, and away. Unlike business which sees ups and downs and takes most functions the same way, IT teams are always looking at expanding their footprint.
And yet, they run into difficulties when push comes to shove. Even large organizations with massive IT budgets and teams of skilled personnel frequently struggle to address the needs of their business-critical applications and workloads, especially when usage surges unexpectedly.
Planning IT architectures upgrades depends not only on the extent of usage, but also business revenue and forecasts – which is why it happens mostly in bursts, as and when requirements peak or budget is available. However, planned scaling and upgrading to a flexible infrastructure ensure business continuity by keeping applications running and prevent loss of revenue or reputation to a large extent.
Today, scaling an enterprise infrastructure can be approached from two angles: cloud environments and on-premises data centers. Most enterprises, medium-sized businesses, and funded startups have deployed a hybrid infrastructure with multiple cloud environments at this point.

While scaling such an infrastructure could be as simple as buying a few extra users off a public cloud provider or adding a server to the rack, there needs to be a balance between the organization’s SaaS, IaaS and data center infrastructure strategies.
For this, the organization needs to know the ways in which it can scale and the options available to it.
The Two Types of Scaling: Scale Up and Scale Out
For a long, long time, the only way to improve the performance of IT systems and applications was to throw better hardware resources into the mix – adding high-capacity memory, buying faster CPUs or plugging in more storage arrays. This is called scaling up or scaling vertically.
Along came Google in 1998 and built the world’s most used web application, and ran it on racks of cheap, commodity servers in data centers distributed across the globe. This kind of infrastructure scales by the numbers – if the application demands more compute power or storage for data, more servers (with similar configurations) are added to the data center. Ditto if one or more stop working, while the architecture routes itself around the failure. This is called scaling out or scaling horizontally.
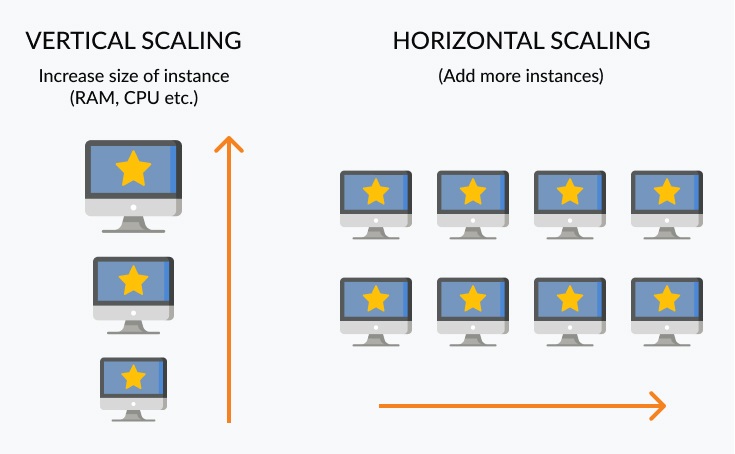
Scaling up basically involves adding more memory, CPU, disk I/O, or network I/O resources to existing instances. With public cloud providers such as Azure and AWS, scaling is done by increasing the sizes of the instances – be it EC2 instances or RDS databases. Vertical scaling is fast and simple. These characteristics make it attractive to SMBs and growing startups; however, they often limit the extent of the scalability.
Other advantages of vertical scaling include:
- Upgrading one server consumes less power than running multiple servers together.
- Managing and installing a single piece of hardware is simpler and easier.
- Existing software is more often than not built to facilitate vertical scaling.
Disadvantages could be:
- Costs of upgrading are usually greater.
- There’s a greater risk in availability. A hardware failure can potentially cause a greater outage.
- Vendor lock-in is a distinct possibility. This imposes technology-specific limits on the infrastructure.
Scaling out, paradoxically, uses limits to extend scalability – it works by limiting the number of requests sent to a particular instance by splitting the workload between multiple instances (which are added as and when needed). This has a twofold advantage: One, it maintains performance regardless of the size of the instance. Two, it ensures high availability – instances can be dynamically added without any downtime, which is not possible in most cases with vertical scaling. Therefore, scaling out is the preferred method for expanding the infrastructure in enterprises, especially global tech giants (including the big 3 cloud providers).

There are some more advantages to horizontal scaling:
- The CAPEX of adding commodity hardware and technology is less, leading to overall cost savings in expanding the infrastructure.
- There is a high level of fault tolerance, as there are more avenues for load balancing, duplication, and replication.
- Theoretically, there is no limit to scaling (again, because of widely available, cheap hardware). An admin can always add another server – whether or not it is fully utilized, it can field more traffic.
The cons of horizontal scaling include:
- More devices running in parallel means utility, energy, and space costs go up.
- The number (and variety) of software out there that can scale to take advantage of horizontal scaling is limited. The software itself is not simple to build, run and manage – handling data distribution and parallel processing routines are complex tasks.
- Security is spread thin. The more nodes there are in a shared architecture, the harder they are to defend.
Criteria for Scaling the IT Infrastructure: What to Consider
What is an organization ideally looking for when considering a change in the existing architecture in its environments?
Like everything else, modernizing an infrastructure starts with asking and answering questions. And then making a plan.
A major part of the infrastructure upgrade plan is identifying the problems or bottlenecks that are affecting it at present. This is not simple with every workload or application; problems are not always noticeable at the outset and might grow slowly over time. For a given workload, this could be pages loading slowly, network connections timing out, and so on. For applications, development-related issues assume monstrous proportions – when development, testing, and production environments no longer match, code becomes harder to test, finding and resolving bugs becomes difficult, and adding new features takes much longer.

It is even more important to be sure that scaling is the solution. The additional resources themselves might introduce new complexities. At an application level, the goal of any scaling solution should be to make your web app or services stack handle common requests more efficiently. These include:
- Web server overload: Simply scale up to a more powerful server. Big data or HPC workloads need nodes or servers that are more powerful than usual. Go for flexible server sizing in cloud environments.
- Single point of failure: Scale out and set up multiple servers that host the same application. Replicate databases using a master-slave architecture where read requests are sent to slaves while write requests are sent to the master.
- Traffic distribution: Use multiple load balancers. Cost effective hardware and software solutions in the cloud are easily available today.
- Factoring sessions: Web apps that use sessions run into trouble when multiple servers or load balancers are used. Decouple sessions using a distributed store such as Redis (and add redundancy for it) to get around this problem.
- Database query overload: A huge application that serves thousands of users with millions of real-time requests soon overruns its cache. Using queues and clearing the cache of inactive users or sessions periodically helps overcome this problem.
- Platform flexibility: Cloud vendors often restrict the OS and applications that run on their platforms, impacting the organization’s strategic technology decisions. Choose open platforms that support multiple software add-ons and come with common apps pre-installed for convenience.
Once the problems are identified and scaling is deemed to be the most effective solution, the next step is to perform an infrastructure audit. The technical architect needs a complete understanding of every workload in the system and how each of them is expected to grow over the next few quarters or years. Any historical data on hardware or software upgrades could prove crucial in identifying potential risks to scaling, zero in on the best solutions and ensuring business continuity throughout the process.

With a clear understanding of the existing resources, operational processes, traffic patterns, and how gaps and growths in each area will align with business goals, the project owner can start making decisions on geographical location of new resources, hosting, cloud vendors, and so on.
Factors Influencing the Scaling Process
As with anything related to IT infrastructure and architecture, a hybrid approach to scaling is probably best. It involves several key factors.
People:
At every phase of scaling, insights and opinions of a diverse team of senior IT personnel from different roles (including system admins, data architects, and DevOps engineers) matters. They need to be fully aware of resource constraints, conduct a clear and transparent assessment of the current infrastructure, devise a roadmap for migration and upgrades, and be able to solve different architecture and implementation challenges as soon as they crop up.
Automation:
A key decision is whether the scaling will be accomplished manually or if it will be automated. Barring certain advanced and complex vertical scaling scenarios where skilled human input is needed for configuration changes, manual scaling is prone to estimation errors and inefficiencies.
Automatic scaling (or autoscaling), on the other hand, enables dynamic addition or removal of CPU, memory, and storage resources whenever utilization rates go above or below pre-defined thresholds. The key advantages here are availability and efficient resource utilization. Based on user demands and traffic patterns, admins can schedule these scaling and provisioning tasks.
Emerging technology is always a key enabler in the efficient scaling. Infrastructure as Code (IaC) is one that facilitates the smooth provisioning of cloud resources, as well as migration of legacy systems to the cloud. It handles configuration and provisioning in the same way as application code, with templates for reproduction, automated scripts for configuration, and storage and access of config files with version control.
Data:
More than any other computing workload of the moment, those involving big data need high performance infrastructure the most. Bottlenecks in compute and storage can quickly cripple workloads that access and transfer large-scale datasets. Applications built for big data workloads need scalable but cost-effective storage solutions combined with superfast I/O, memory and processing power scaling capabilities. Companies that work with big data (who doesn’t?) therefore need a versatile cloud or on-premises scaling option that fluidly meet these storage performance needs.
HCI: Up, Up and Out
With the kind of cloud and data center resources available today, it’s not enough for any architecture to just scale up or out – it should be able to do both. Simultaneously. On demand.
This is where hyperconvergence is pushing the frontiers.
In the pre-hyperconvergence era, when vertical scaling was the norm, one or more physical servers or storage devices were added to the data center whenever an application needed to be scaled up. This 1:1 application-to-server or application-to-storage model was highly inefficient because either of the latter remained largely idle, owing to partial utilization or limited by memory or processing power (which was usually added later as and when budgets permitted). To compound the problem, management of the usually disparate hardware and software was painful for lack of unification and centralization.
Server virtualization technology brought considerable relief to this inefficiency – provisioning left room to add more VMs without the need to purchase physical hardware. Then, hyperconvergence arrived and took virtualization to the next level, enabling the clustering of all compute and storage resources into a single, shared resource pool. In fact, improved scalability is one of the top three benefits realized by organizations that have adopted a hyperconverged infrastructure (HCI).

In an HCI, all resources can scale together at once or independently when needed. A HCI scales out in finite, integrated, and modular blocks (called nodes) of compute, memory, and storage units. When a cluster is out of capacity, an admin can create new nodes from additional physical devices and scale up the infrastructure within minutes.
One of the biggest advantages of HCI is that the entire stack, consisting of on-premises as well as hybrid cloud environments can be managed via a ‘single pane of glass’ interface.
All infrastructure modernization and upgrade planning should be driven by cost optimization and performance efficiency. At every stage, CTOs and CIOs need to focus on virtualization, hyperconvergence, private, public and hybrid cloud. It’s critical to address workloads with an architecture that has fewer, denser nodes that fully utilize the raw processing power, memory and storage available to them.

Dipti Parmar is a marketing consultant and contributing writer to Nutanix. She writes columns on major tech and business publications such as IDG’s CIO.com, Adobe’s CMO.com, Entrepreneur Mag, and Inc. Follow her on Twitter @dipTparmar and connect with her on LinkedIn.
© 2021 Nutanix, Inc. All rights reserved. For additional legal information, please go here.
Related Articles









