Executive Summary
In this article, we present a Large Language Model (LLM) agent, engineered to perform both language generation and decision tracing . This agent's decision faculty adapts to the query context and semantics. The development of this LLM agent was conducted using the Nutanix Cloud Platform™, showcasing its robust capability in managing intricate workflows.
Introduction
Large language model (LLM) predicts the next token from a context. It has produced state-of-the-art performance on different Natural Language Processing (NLP) benchmarks. However, LLMs mostly act as a black box with minimum visibility into its reasoning and generation process. The ability of LLMs have been studied in two different directions: reasoning (e.g., chain-of-thought) and action (e.g., action plan generation). The current LLM literature has put considerable focus on synergizing the reasoning traces and the task-specific actions in an interleaved manner bringing more transparency into LLM. Such an approach effectively transforms an LLM from a mere computational tool into an agentic entity. By doing so, LLMs are not only able to demonstrate intelligent reasoning but also to adaptively select and execute actions. This evolution marks a significant stride towards endowing LLMs with a more dynamic and interactive capability, bridging the gap between artificial intelligence and human-like cognitive processing. LLM agents in general come in the realm of constitutional AI.
Enterprises can reap rich benefits from the flexibility of LLM agents. In the evolving landscape of Enterprise Software 2.0, LLM agents are poised to become the central operational hubs within enterprise software ecosystems. These LLM agents are envisaged as not only industry experts but also as pivotal decision-makers. Their functionality extends to understanding and applying domain-specific knowledge in enterprise contexts. Moreover, they are designed to dynamically leverage various tools, facilitating the automation of task completion. This integration signifies a transformative shift towards more intelligent, efficient, and automated enterprise systems.
LLM Agent Workflow
Stateful LLM Response Class Generation
A stateful LLM response object keeps track of the underlying processes that go in creating an LLM response from a query. Therefore, it can capture the traces of different steps in the generation process.
Action Choice Template
An action choice template includes all the action choices and their respective implementations.
Design Prompt Template for Reasoning Traces
A prompt template for reasoning traces uses chain-of-thought (CoT) to elicit the intermediate reasoning of LLM.
Heuristic/RL-based Collection of Reasoning and Action
In Heuristic/RL-based collection for reasoning and action, all three previous components are combined to produce an online LLM agent which takes a query and generates a response.
 Figure 1: Workflow of an LLM Agent
Figure 1: Workflow of an LLM Agent
At Nutanix, we are dedicated to enabling customers to build and deploy intelligent applications anywhere—edge, core data centers, service provider infrastructure, and public clouds. Figure 2 shows how AI/ML is integrated into the core Nutanix® infrastructure layer. RLHF is a key workflow in the development of AI Applications at the top.
 Figure 2: AI stack running on the cloud-native infrastructure stack of NCP. The stack provides holistic integration between supporting cloud-native infrastructure layer, including chip layer, followed by virtual machine layer, supporting library/tooling layer, and AI stack layer, including Foundation Models (different variants of transformers), task specific AI app layers.
Figure 2: AI stack running on the cloud-native infrastructure stack of NCP. The stack provides holistic integration between supporting cloud-native infrastructure layer, including chip layer, followed by virtual machine layer, supporting library/tooling layer, and AI stack layer, including Foundation Models (different variants of transformers), task specific AI app layers.
As shown in Figure 2, the App layer runs on the top of the infrastructure layer. The infrastructure layer can be deployed in two steps, starting with Prism Element™ login followed by VM resource configuration. Figure 3 shows the UI for Prism Element.
 Figure 3: The UI showing the setup for a Prism Element on which the transformer model for this article was trained. It shows the AHV® hypervisor summary, storage summary, VM summary, hardware summary, monitoring for cluster-wide controller IOPS, monitoring for cluster-wide controller I/O bandwidth, monitoring for cluster-wide controller latency, cluster CPU usage, cluster memory usage, granular health indicators, and data resiliency status.
Figure 3: The UI showing the setup for a Prism Element on which the transformer model for this article was trained. It shows the AHV® hypervisor summary, storage summary, VM summary, hardware summary, monitoring for cluster-wide controller IOPS, monitoring for cluster-wide controller I/O bandwidth, monitoring for cluster-wide controller latency, cluster CPU usage, cluster memory usage, granular health indicators, and data resiliency status.
After logging into Prism Element, we create a virtual machine (VM) hosted on our Nutanix AHV® cluster. As shown in Figure 4, the VM has following resource configuration settings: 22.04 Ubuntu® operating system, 16 single core vCPUs, 64 GB of RAM, and NVIDIA® A100 tensor core passthrough GPU with 40 GB memory. The GPU is installed with the NVIDIA RTX 15.0 driver for Ubuntu OS (NVIDIA-Linux-x86_64-525.60.13-grid.run). The large deep learning models with transformer architecture require GPU or other compute accelerators with high memory bandwidth, large registers and L1 memory.
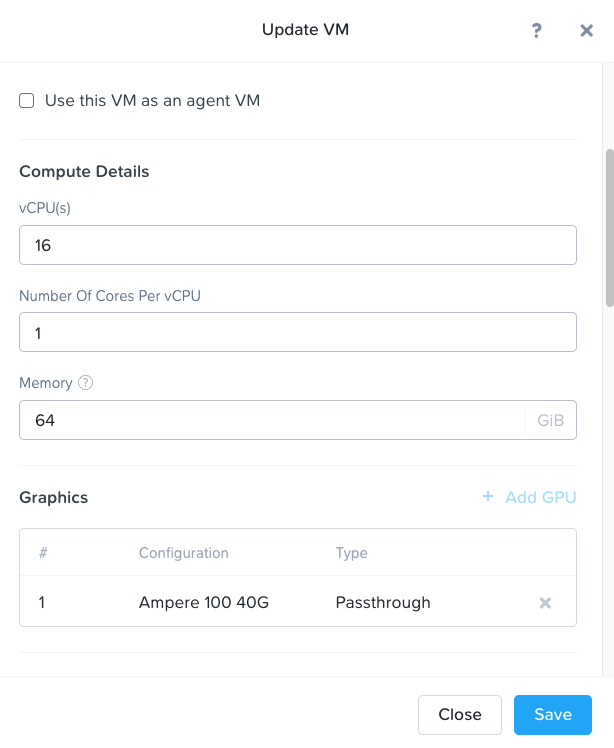
Figure 4: The VM resource configuration UI pane on Nutanix Prism Element. As shown, it helps a user configure the number of vCPU(s), the number of cores per vCPUs, memory size (GiB), and GPU choice. We used an NVIDIA A100 80G for this article.
The NVIDIA A100 Tensor Core GPU is designed to power the world’s highest-performing elastic datacenters for AI, data analytics, and HPC. Powered by the NVIDIA Ampere™ architecture, A100 is the engine of the NVIDIA data center platform. A100 provides up to 20X higher performance over the prior generation and can be partitioned into seven GPU instances to dynamically adjust to shifting demands.
To peek into the detailed features of A100 GPU, we run `nvidia-smi` command which is a command line utility, based on top of the NVIDIA Management Library (NVML), intended to aid in the management and monitoring of NVIDIA GPU devices. The output of the `nvidia-smi` command is shown in Figure 6. It shows the Driver Version to be 515.86.01 and CUDA version to be 11.7. Figure 5 shows several critical features of the A100 GPU we used. The details of these features are described in Table 1.
 Figure 5: Output of `nvidia-smi` for the underlying A100 GPU
Figure 5: Output of `nvidia-smi` for the underlying A100 GPU
Table 1: Description of the key features of the underlying A100 GPU.
Stateful LLM Response Class Generation
The following screenshot shows how an LLM model is encapsulated to produce a stateful class implementation. It stores both input messages and generated responses from an LLM.
 How an LLM model is encapsulated to produce a stateful class implementation
How an LLM model is encapsulated to produce a stateful class implementation
Action Choice Template
The following screenshot shows how we define different actions for the LLM. In this case, the action represents the data feed path for the LLM. It has two choices one from wikipedia and another a simple localized eval function for mathematical tasks. Depending on the question type, the LLM model is capable of smartly choosing the appropriate execution thread.
 How we define different actions for the LLM
How we define different actions for the LLM
Design Prompt Template for Reasoning Traces
The following screenshot shows a CoT based prompt template for keeping track of the reasoning traces.
 CoT based prompt template
CoT based prompt template
Heuristic/RL-based Collection of Reasoning and Action
A Heuristic/RL-based collection of reasoning and action compiles all the intermediate steps as LLM generates a response to a user question. In this screenshot, we show the specific implementation for this article. We use a simple heuristic based stopping criteria for 5 turns. This is something that can be implemented using RL algorithms such as SARSA.
 Specific implementation for this article
Specific implementation for this article
Question 1
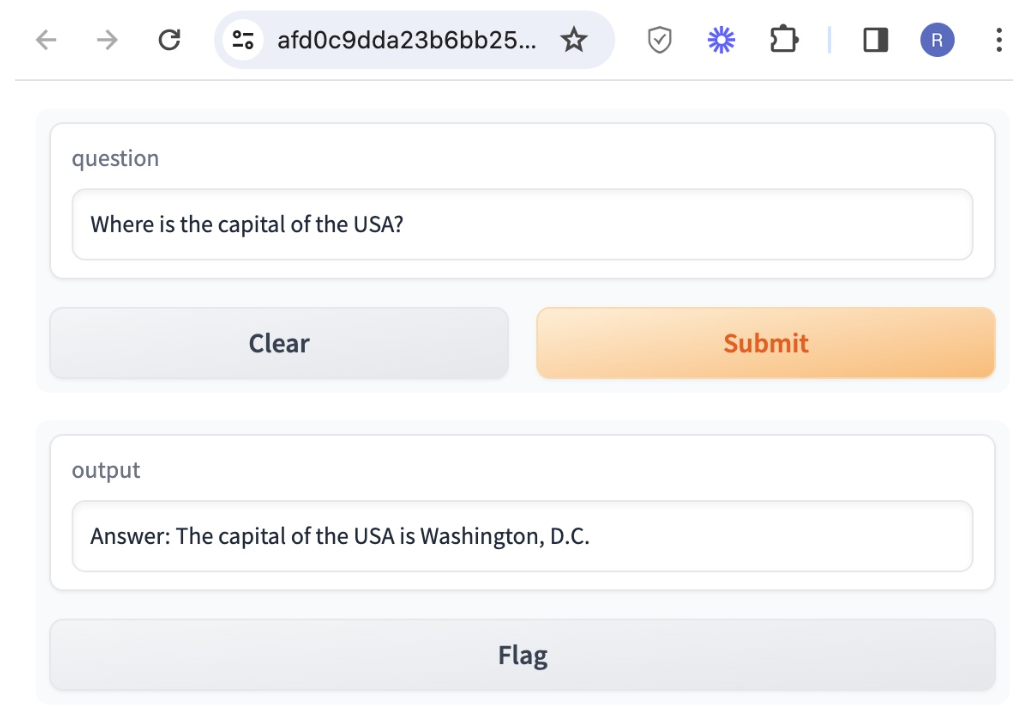
Question 1: Where is the capital of the USA?
This shows how the intermediate Thought, Action as LLM generates answers the question “Where is the capital of the USA?” It can be observed that only 1 turn of reasoning action loop is sufficient to reach the answer. It uses wikipedia search for a factual answer generation.
Question 2
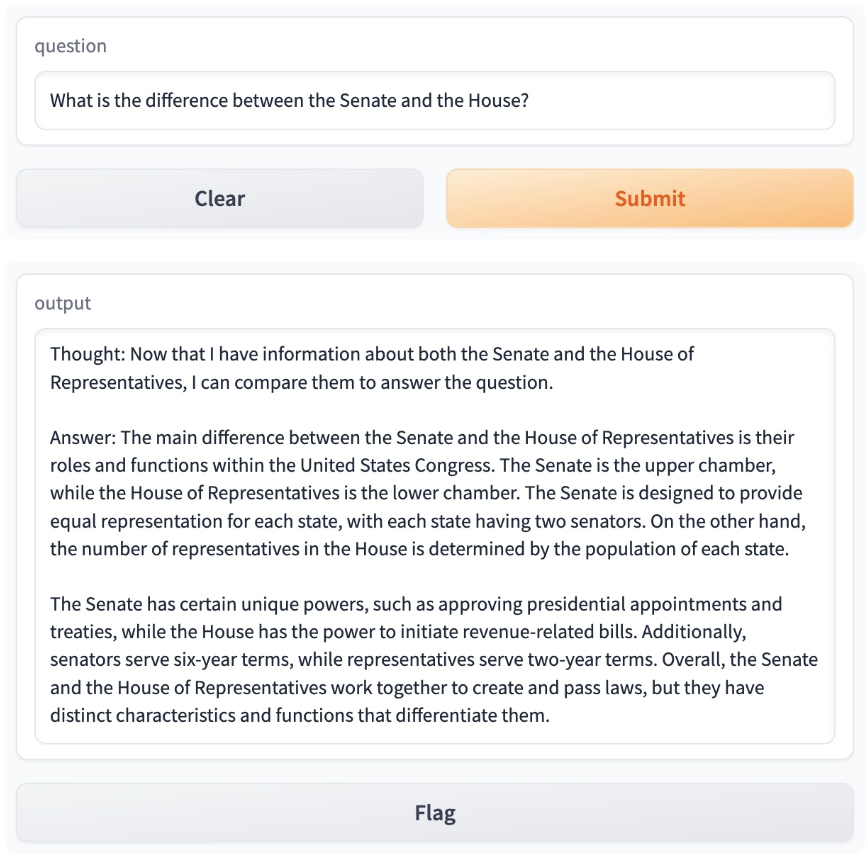
What is the difference between the Senate and the House?
This shows how the intermediate Thought, Action as LLM generates answers the question “What is the difference between the senate and the house?” It can be observed that 2 turns of reasoning action loop are necessary to reach the answer. It uses wikipedia search for a factual answer generation.
Question 3
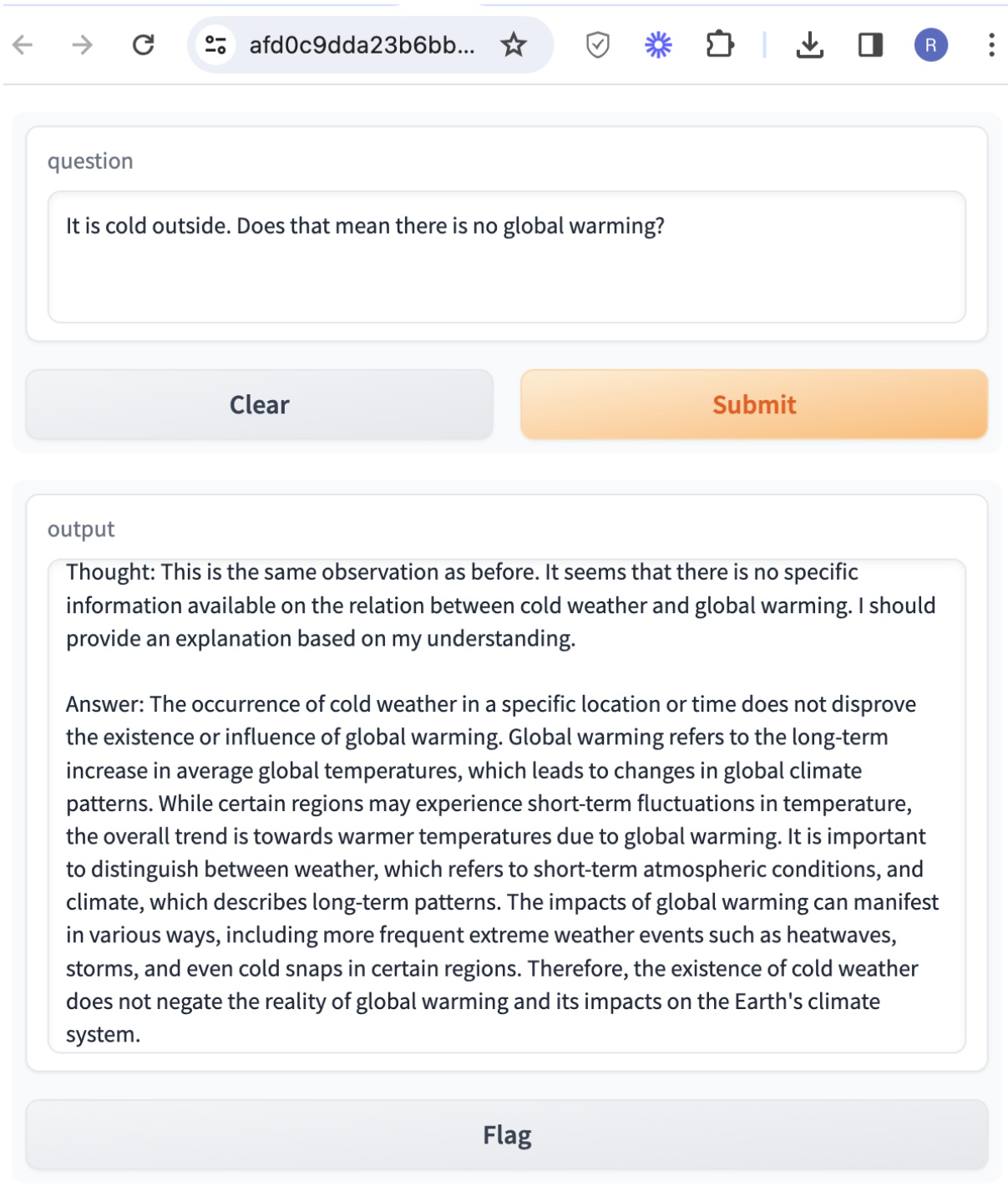
It is cold outside. Does that mean there is no global warming?
This shows how the intermediate Thought, Action as LLM generates answers the question “It is cold outside. Does that mean there is no global warming?” It can be observed that only 1 turn of reasoning action loop is sufficient to reach the answer. It uses wikipedia search for a factual answer generation. Although the answer is factual, in this case LLM uses logical reasoning to derive the final answer.
Question 4
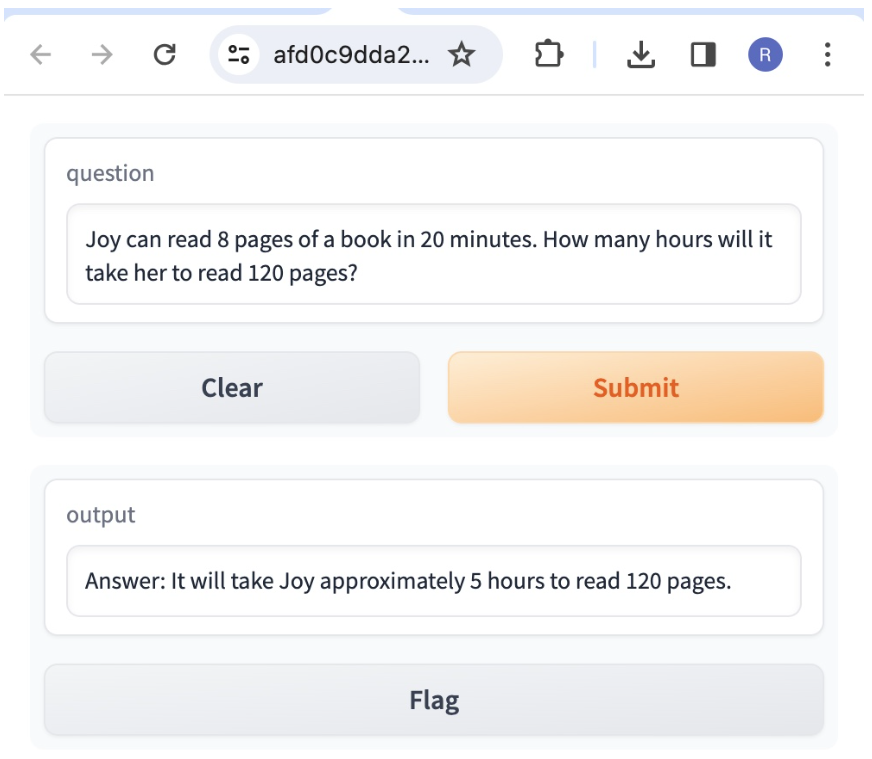
Joy can read 8 pages of a book in 20 minutes. How many hours will it take her to read 120 pages?
This shows how the intermediate Thought, Action as LLM generates answers the question “Joy can read 8 pages of a book in 20 minutes. How many hours will it take her to read 120 pages?” It can be observed that only 1 turn of reasoning action loop is sufficient to reach the answer. It uses the local eval function to derive the final answer to the high school mathematics question.
Question 5
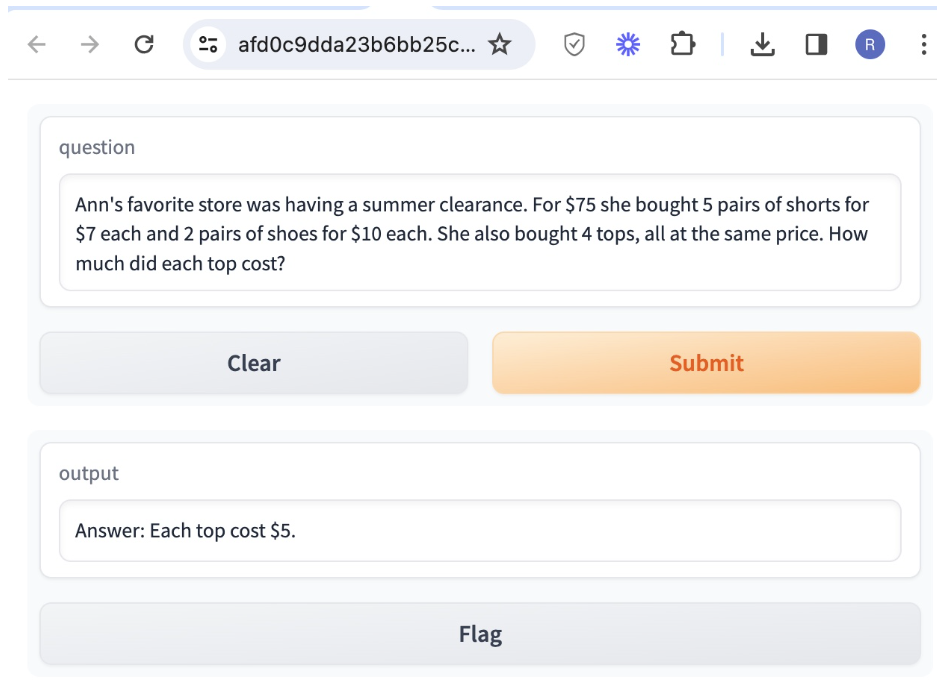
Question: Ann’s favorite store was having a summer clearance. For $75 she bought 5 pairs of shorts for $7 each and 2 pairs of shoes for $10 each. She also bought 4 tops, all at the same price. How much did each top cost?
This shows how the intermediate Thought, Action as LLM generates answers the question “Ann’s favorite store was having a summer clearance. For $75 she bought 5 pairs of shorts for $7 each and 2 pairs of shoes for $10 each. She also bought 4 tops, all at the same price. How much did each top cost?” It can be observed that 2 turns of reasoning action loop are necessary to reach the final answer. It uses the local eval function to derive the final answer to the high school mathematics question.
Empirical Best Practices/Insights
In our exploration with Large Language Model (LLM) agents, while specific generalizations are elusive, certain performance patterns have emerged, offering valuable insights and best practices:
- LLMs typically require a multi-step process to generate answers. Ensuring transparent and traceable reasoning is crucial for clarity and debugging purposes. This can be achieved through a stateful LLM generation loop, allowing the creation of a multi-stage generation process.
- LLM agents are capable of managing multiple action threads simultaneously. Effective prompt engineering, particularly using Chain-of-Thought (CoT) approaches, enables these agents to navigate through various action choices autonomously.
- The integration of a reasoning-action loop within LLM agents can be effectively actualized either through heuristic methods or by employing reinforcement learning-based sequential decision-making strategies.
© 2024 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product, feature and service names mentioned herein are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. Other brand names mentioned herein are for identification purposes only and may be the trademarks of their respective holder(s). This post may contain links to external websites that are not part of Nutanix.com. Nutanix does not control these sites and disclaims all responsibility for the content or accuracy of any external site. Our decision to link to an external site should not be considered an endorsement of any content on such a site. Certain information contained in this post may relate to or be based on studies, publications, surveys and other data obtained from third-party sources and our own internal estimates and research. While we believe these third-party studies, publications, surveys and other data are reliable as of the date of this post, they have not independently verified, and we make no representation as to the adequacy, fairness, accuracy, or completeness of any information obtained from third-party sources.
This post may contain express and implied forward-looking statements, which are not historical facts and are instead based on our current expectations, estimates and beliefs. The accuracy of such statements involves risks and uncertainties and depends upon future events, including those that may be beyond our control, and actual results may differ materially and adversely from those anticipated or implied by such statements. Any forward-looking statements included herein speak only as of the date hereof and, except as required by law, we assume no obligation to update or otherwise revise any of such forward-looking statements to reflect subsequent events or circumstances


